
'분류 전체보기'에 해당되는 글 956건
- 2011.04.03 :: azotic compounds laboratory dance the night away
- 2011.04.03 :: Bill Evans - April in Paris
- 2011.03.31 :: 기본적 문제풀이법
- 2011.03.30 :: 책 읽기의 달인, 호모부커스
- 2011.03.29 :: 전이해 사전지식을 통해 책에 대한 이해력을 높인다
- 2011.03.28 :: adg
- 2011.03.28 :: 너라디오
- 2011.03.27 :: ㅇ
- 2011.03.27 :: 국어국문학 국어의미론
- 2011.03.26 :: 11
기본적인 문제풀이 방법
인공지능 : Elaine Rich 저서, 유석인.전주식.한상영 편역, 상조사, 1986 (원서 : Artificial Intelligence, McGraw-Hill, 1983, Artificial Intelligence (2nd ed, 1991)), Page 69~123
|
(1) 해답의 생성과 테스트 방법 (Generate-and-Test) (3) 나비 우선 탐색 방법 (Breadth-First Search) (4) 최적 우선 탐색 방법 (Best-First Search) : OR 그래프 (5) 문제 축소 방법 (Problem Reduction) (6) 제한 조건의 만족 방법 (Constraint Satisfaction) |
지금까지 인공 지능 분야의 문제들은 대부분, 직접적인 기법으로는 풀 수 없을 만큼 복잡하다는 것을 알았다 : 오히려 적절한 탐색 방법과 이 탐색을 유도하기 위해 이용될 수 있는 직접적인 기법을 함께 사용하여 이 문제들을 해결해야 한다. 이 장에서 논의될 범용 탐색 기법은 모두 경험적 탐색 방법의 일종이다. 이 기법들을 특정한 작업이나, 문제 영역에 관련짓지 않고 설명할 수 있지만, 특정한 문제에 적용하는 경우, 영역 특성에 대한 지식을 이용하는 방법에 따라 적용된 기법의 효율성이 결정된다. 왜냐하면, 기법 자체로는 탐색 과정에서 발생하기 쉬운 실행 시간의 폭발적 급증을 해결할 수 없기 때문이다. 이러한 이유 때문에 이 기법들을 불완전 방법 (weak methods) 이라 한다. 지난 20 년 동안, 인공 지능 분야의 어려운 문제들을 풀기 위해 - 미흡한 점이 있지만 - 이 불완전 방법이 사용되었으며, 영역 특성에 대한 지식을 위치시킬 틀을 제공하며, 인공 지능 시스템의 핵심을 이루어 왔다.
모든 탐색 과정을 방향성 그래프의 탐색으로 볼 수 있는데, 그래프는 문제의 상태를 나타내는 노드와, 노드간의 관계를 나타내기 위해 두 개의 노드를 연결하는 링크로 구성된다. 예를 들면, 그림 5 는 물 주전자 문제를 나타낸 탐색 그래프이다. 그림에서 알 수 있듯이, 각 링크에는 명칭이 주어지지 않았지만, 이들 링크는 물을 붓는 적당한 작용과 대응한다. 탐색 과정은 그래프 상에서 출발 상태로부터 시작하여 하나 혹은 그 이상의 최종 상태에서 끝나는 경로를 찾아낸다. 원칙상, 문제 영역에서 허용 가능한 움직임을 정의하는 모든 규칙들을 사용하여 탐색 그래프를 만들어야 하지만, 이렇게 하여 얻은 그래프는 매우 크며, 또한 사실상 그래프의 모든 경로가 탐색되는 것이 아니고, 대부분의 경로는 탐색될 필요도 없기 때문에, 그래프를 명시적으로 만들어 탐색하는 대신, 주어진 규칙을 사용하여 암시적으로 그래프를 표기한 후 탐색할 부분만을 명시적으로 나타낸다. 탐색 과정을 논의할 때, 암시적 탐색 그래프와 탐색 프로그램에 의해 실제로 만들어진 명시적 부분 탐색 그래프간의 차이를 명심해야 한다.
탐색 방법을 각각 개별적으로 설명하기에 앞서, 모든 탐색 과정 중에 발생하는 다음 다섯 가지의 중요한 문제점들을 살펴 보자 :
다음 다섯 개의 절에서 이러한 문제들이 다루어진다.
1. 전진 추론과 후진 추론
문제 영역 내에서 출발 상태로부터 목표 상태로 가는 경로를 찾는 것이 탐색 과정이 목표이다. 이러한 탐색은 다음 두 가지 방향으로 수행할 수 있다.
- 출발 상태로부터 전진
- 목표 상태로부터 후진
탐색 과정의 생성 시스템 모델을 사용하여 전진과 후진을 대칭적인 것으로 오는 방법을 찾을 수 있다. 특별한 8-퍼즐의 예를 푸는 문제를 살펴 보자. 퍼즐을 풀기 위한 규칙이 그림 1 에 나와 있고, 이 규칙을 사용하여 그림 2 의 퍼즐을 전진 추론으로도, 후진 추론으로도 풀 수 있다.
- 출발 상태로부터의 전진 추론 : 출발 상태를 루트로 하여 문제를 풀기 위한 일련의 움직임을 나타내는 트리를 만든다. 좌측면이 루트 노드와 일치하는 규칙을 모두 찾아 이 규칙의 우측면을 사용하여 다음 레벨의 노드를 만든다. 전 레벨의 각 노드에 대해 좌측면이 이 노드와 일치하는 규칙을 모두 찾아 이 규칙의 우측면을 이용하여 다음 레벨을 만든다. 목표 상태와 일치될 때까지 이 과정을 계속 수행한다.
|
각 정사각형에 다음과 같은 숫자가 주어졌다고 가정하자. | ||||
|
|
1 |
2 |
3 |
|
|
|
4 |
5 |
6 |
|
|
|
7 |
8 |
9 |
|
|
정사각형 1 은 비어 있고, 정사각형 2 는 타일 n 을 가지고 있다. → 정사각형 2 는 비어 있고, 정사각형 1 은 타일 n 을 가지고 있다. 정사각형 1 은 비어 있고, 정사각형 4 는 타일 n 을 가지고 있다. → 정사각형 4 는 비어 있고, 정사각형 1 은 타일 n 을 가지고 있다. 정사각형 2 는 비어 있고, 정사각형 1 은 타일 n 을 가지고 있다. → 정사각형 1 은 비어 있고 정사각형 2 는 타일 n 을 가지고 있다. . . . | ||||
그림 1 8-퍼즐을 푸는 규칙의 예
|
출발 상태 |
|
목표 상태 | ||||
|
2 |
8 |
3 |
|
1 |
2 |
3 |
|
1 |
6 |
4 |
|
8 |
|
4 |
|
7 |
|
5 |
|
7 |
6 |
5 |
그림 2 8-퍼즐의 예
- 목표 상태로부터의 후진 추론 : 목표 상태를 루트로 하여 문제를 풀기 위해 사용될 일련의 움직임을 나타내는 트리를 만든다. 오른쪽면이 루트 노드와 일치하는 규칙을 모두 찾아, 규칙의 왼쪽면을 사용하여 트리의 다음 레벨을 구성한다. 전 단계의 각 노드에 대해 오른쪽면이 이 노드와 일치하는 모든 규칙을 찾아 이 규칙에 대응하는 왼쪽면을 사용하여 다음 레벨의 노드를 만든다. 새로이 만들어진 노드가 출발 상태와 일치할 때까지 이 과정을 계속 수행한다. 원하는 목표 상태로부터 후진 추론하는 방법을 목표로부터 출발하는 추론 (goal-directed reasoning) 혹은 후진 연쇄에 의한 추론 (backchaining) 이라 한다.
전진 추론과 후진 추론에서 모두 동일한 규칙이 사용된다. 규칙이 전진 추론에 사용될 경우, 왼쪽면 (선결 조건) 이 현재 상태와 일치하는 규칙을 찾아, 목표 상태에 도달할 때까지 새로운 노드를 만들기 위해 이 규칙의 오른쪽면 (결과) 을 사용한다. 후진 추론에 사용될 경우, 오른쪽면이 현재 상태와 일치되는 규칙의 왼쪽면을 새로운 노드를 만들기 위해 사용한다. 새로이 만들어진 노드는 도달해야 할 새로운 목표 상태를 의미하며 새로이 얻은 목표 상태 중의 하나가 출발 상태와 일치할 때까지 수행을 계속한다.
8-퍼즐의 경우, 전진 추론과 후진 추론에 그다지 큰 차이가 없다 : 두 경우 모두 동일한 수의 경로를 조사한다. 그러나 모든 문제에 대해 항상 그런 것이 아니며, 문제 영역의 배치 구조에 따라 전진 추론이 더 효과적일 때도 혹은 후진 추론이 효과적일 때도 있다. 다음 세 가지의 요인에 의해 추론의 방향이 결정된다 :
- 가능한 출발 상태의 수가 더 많은가 혹은 가능한 목표 상태의 수가 더 많은가? 가능한 상태의 수가 더 작은 쪽에서 더 많은 쪽으로 수행하는 것이 효율적이다.
- 어느 족의 분기 계수가 더 큰가? 분기 계수가 작아지는 방향으로 추론하는 것이 효과적이다.
- 사용자가 추론 과정의 올바름을 증명하도록 프로그램에 요구하였는가? 만약 그렇다면, 사용자의 사고 방향과 가까운 방향으로 추론해야 한다.
다음 몇 가지 예를 사용하여 위의 문제들을 명백히 해 보자. 집과 낯선 장소를 연견하는 길을 찾는 문제를 살펴 보자. 양쪽 어느 곳에서든지 시작할 수 있다. 집으로부터 낯선 장소로 가는 것보다, 낯선 장소에서 집으로 오는 것이 효과적이다. 그 이유는 다음과 같다. 분기 계수는 어느 쪽에서 시작하든지 거의 비슷하다. 그러나 양쪽을 연결하는 길을 찾을 때 낯선 곳으로 간주되는 장소보다 집으로 간주될 수 있는 장소가 더욱 많다. 즉, 집과 그것을 연결하는 길을 이미 알고 있는 장소는 집으로 생각할 수 있다. 만약 집과 낯선 장소를 연결하는 길을 찾는 과정에서 그런 장소를 찾기만 하면 쉽게 집으로 갈 수 있다. 이것은 집과 낯선 장소간의 길을 찾는 문제의 경우 낯선 장소로부터 후진 추론하여 길을 찾는 것이 효율적이라는 것을 의미한다.
반면, 적분 문제를 살펴보자. 문제 영역은 공식들의 집합이며, 여기에 적분식도 포함되어 있다. 출발 상태는 적분식을 포함하고 있는 특정한 공식이며, 원하는 목표 상태를 처음 식과 동치이며, 어떠한 적분식도 포함하지 않는 공식이다. 하나의 출발 상태와 매우 많은 가능한 목표 상태를 가지고 문제를 풀기 시작한다. 따라서 이 문제를 풀기 위해서는, 적분식이 포함되어 있지 않는 임의의 식에서 출발하여, 미분 공식을 이용해 원하는 특별한 적분식을 만드는 것보다, 적분식에서 출발하여 적분이 포함되어 있지 않은 식으로 전진 추론하는 것이 효과적이다. 가능한 여러 개의 목표 상태 중 하나의 목표 상태를 향해 나가는 것, 즉 전진 추론을 하는 것이다. 위의 두 예는 양쪽 방향에서의 분기 계수가 거의 같을 때, 출발 상태와 목표 상태의 상대적인 수가 추론의 방향을 결정하는데 미치는 중요성을 설명한다. 그러나 분기 계수가 비슷하지 않을 경우 이 또한 추론 방향을 결정하는데 고려되어야 한다.
수학의 정리를 증명하는 문제를 살펴 보자. 목표 상태는 증명될 정리이고, 출발 상태는 공리의 작은 집합이다. 출발 상태의 수와 목표 상태의 수가 거의 비슷하다. 그러나 각 방향으로 추론할 때의 분기 계수를 살펴 보자. 몇 개 안되는 공리를 가진 집합으로부터 이들을 이용하여 매우 많은 수의 정리를 만들 수 있다. 반면, 매우 많은 정리로부터 몇 개 안되는 공리로 이루어진 집합으로 후진 추론할 수 있다. 정리로부터 공리로 후진 추론할 때의 분기 계수는 공리로부터 전진 추론할 때의 분기 계수보다 훨씬 작다. 이로부터 정리를 증명할 때는 전진 추론이 더욱 효율적임을 알 수 있다. 정리를 증명하기 위해 어느 방향으로든 추론할 수 있지만, 앞에서 언급한 이유 때문에 후진 추론을 사용하는 비교 흡수 방법 (resolution) 이 주로 사용된다.
탐색의 진행 방향을 결정하는 세번째 요인, 즉 추론 과정이 진행됨에 따라 이것이 논리적으로 정당한가를 증명할 필요가 있는지의 문제에 대해 살펴 보자. 이것은 매우 중요한 작업을 수행하는 프로그램의 결과를 인정해야 할지 결정하는데 중요하다. 의사는 자신이 만족할 만큼 충분히 추론을 설명할 수 없는 진단 프로그램의 충고는 받아들일 수 없다. 전염병을 진단하는 프로그램인 MYCIN 을 작성할 때 이 문제가 고려되었다. 이 프로그램은 환자의 병에 대한 원인을 결정하는 목표 상태로부터 후진 추론한다. "만약 유기체가 실험실에서 얻은 결과로부터 결정된 다음 특성을 가졌다면, 이것은 유기체 X 일 확률이 높다." 등을 말하는 규칙이 후진 추론을 위해 사용된다. 이 규칙을 사용하여 후진 추론하여, 프로그램은 "그것은 유기체 X 의 존재 여부를 결정하는데 도움이 되기 때문이다" 라는 답을 가진 "내가 당신이 요구한 테스트를 수행하는 이유는 무엇인가?" 와 같은 문제에 답할 수 있다.
이 장에서 논의될 대부분의 탐색 기법은 전진 혹은 후진 어느 쪽이든지 탐색을 위해 사용될 수 있다. 생성 규칙의 집합을 적용하는 것으로 탐색을 설명한다면, 탐색 방향과 무관하게 특수한 탐색 알고리즘을 쉽게 기술할 수 있다. 이것에 대한 한 가지 예외는 3-6-7 절에서 설명될 방법 - 목적 분석 방법 (means-ends analysis) 인데, 이것은 한 방향으로만 계속 추론하는 것이 아니라, 현재 상태와 목표 상태간의 차이를 줄이는 방향으로 추론을 진행하는 것으로, 이를 위해 때로는 전진 추론이 때로는 후진 추론이 사용된다.
추론의 또 다른 방법은 출발 상태로부터의 전진 추론과 목표 상태로부터의 후진 추론을 동시에 추론 경로의 중간 어느 지점에서 만날 때까지 계속 수행하는 양쪽 방향 탐색 (bidirectional search) 이다. 이것은 각 레벨의 노드 수가 지금까지 얻은 레벨의 수에 지수 함수적으로 증가할 때 효과적이다. 그림 3 은 양쪽 방향 탐색이 비효율적인 이유를 나타낸다.
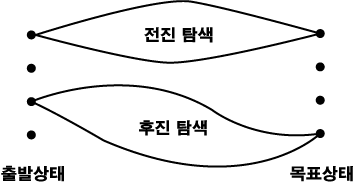
그림 3 잘못 사용된 양쪽 방향 탐색의 예
2. 문제 트리와 문제 그래프
탐색 방법을 구현하는 간단한 방법은 트리 트래버설 (tree traversal) 이다. 후계 노드를 만들기 위해 트리의 각 노드들이 사용되는 규칙에 의해 전개되는데, 풀이를 나타내는 노드가 발견될 때까지 이 각 노드들을 다시 전개, 팽창한다. 그림 4 는 물 주전자 문제의 탐색 트리를 나타낸다. 이 과정은 쉽고 간단하게 구현되며, 장부 정리 즉, 전후 상황의 기록도 거의 불필요하다. 그러나 이 과정에서 이미 한번 이상 수행된 노드가 다시 발생할 수 있다. 이것은 사실상 방향성 그래프로 탐색하는 것이 적합한 문제를 트리로 처리했기 때문에 발생한다.
예를 들면, 그림 4 의 트리에서 한 주전자에는 4 갈론의 물이, 다른 하나에는 3 갈론의 물이 들어 있음을 나타내는 노드 (4, 3) 은 먼저 4 갈론 들이의 물 주전자를 채운 뒤, 3 갈론 들이의 물 주전자를 채우거나 그 반대의 순서로 물 주전자를 채울 때 얻어진다. 이 문제의 경우, 수행 순서가 중요하지 않기 때문에 이 두 노드를 계속 수행할 필요가 없다. 이 예로부터 트리를 따라 탐색 과정을 수행할 때 발생하는 또 다른 문제를 알 수 있다. 세번째 레벨이 노드 (0, 0) 가 있다 (사실, 이것은 두 번 나타난다). 그러나 이것은 트리의 루트 노드와 동일한 것으로써 이미 전개, 팽창되었다. 이 개의 경로는 새로운 노드로 확장되지 못하기 때문에, 이것들을 없애고 나머지 다른 경로를 따라 수행을 계속하면 효과적이다.
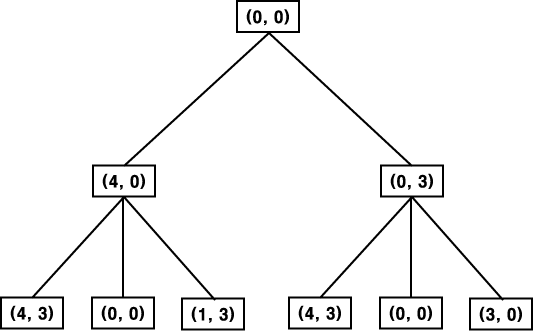
그림 4 나비 우선 탐색 트리의 두 레벨
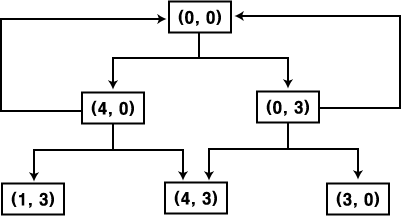
그림 5 물 주전자 문제의 탐색 그래프
동일한 노드가 한번 이상 만들어질 때 소모되는 노력의 낭비를 다음과 같은 작업을 첨가하여 피할 수 있다. 탐색 트리를 트래버셜하는 대신 방향성 그래프를 트래버셜 한다. 한 노드가 여러 개의 경로에 포함될 수 있다는 전에서 그래프는 트리와 다르다. 그림 4 의 트리에 대응하는 그래프가 그림 5 에 있다. 노드가 생성될 때마다 수행되는 작업을 수정하여 트리의 탐색 과정으로 변환시킬 수 있다. 생성된 노드를 단순히 그래프에 첨가하는 대신 다음과 같은 일을 한다 :
1. 새로운 노드가 이미 존재하는 것인지의 여부를 위해 지금까지 만들어진 노드들을 조사한다.
2. 존재하지 않는다면, 다음 두 가지 일을 수행한다 :
1) 새로이 확장하는 대신, 이미 존재하는 후계 노드를 가르키도록 연결하여, 새로 만들어지는 노드는 무시한다.
2) 만약 각 노드에 대한 최적 경로 (최단 거리 혹은 최소 비용) 를 기억하고 있다면, 새로운 경로가 이미 존재하고 있는 경로보다 더 좋은지 혹은 더 나쁜지를 조사한다. 만약 이미 알고 있는 경로보다 더 나쁘다면 아무 일도 하지 않는다. 그러나 이미 알고 있는 경로보다 더 좋다면, 이 새로운 경로를 그 노드를 포함하는 올바른 경로로 기억시키고, 만약 필요하다면 해당되는 비용 절감의 변화를 후계 노드를 통하여 전달한다.
여기서 발생하는 한 가지 문제점은 탐색 그래프에 나타나는 사이클 (cycle) 이다. 사이클은 그래프상에 한 번 이상 나타나는 노드를 포함하고 있는 경로이다. 예를 들어 그림 5 에는 길이가 2 인 사이클이 수 개 포함되어 있다. 하나는 노드 (0, 0) 와 노드 (4, 0) 으로, 다른 하나는 노드 (0, 0) 과 노드 (0, 3) 으로 다루어진 경로이다. 사이클이 존재하면, 경로의 길이를 특정한 하나의 값으로 정할 수 없기 때문에 그래프 트래버셜 알고리즘의 종료를 보장할 수 없다.
트리 대신 그래프를 탐색함으로써 같은 경로를 여러 번 조사할 때 소모되는 노력을 절감할 수 있지만 그래프의 탐색을 위해서는 새로이 만들어지는 각 노드에 대해 이미 존재하는지의 여부를 결정해야 하는 부가적인 노력이 요구된다. 문제에 따라 이 노력이 받아들여질 수도 혹은 받아들여지지 않을 수도 있다. 만약 동일한 노드가 여러 다른 방법에 의해 만들어질 수 있다면 그래프 탐색 과정을 사용하는 것이 더욱 효과적이다. 그래프 탐색 과정을 적용되는 연산들의 어떠한 순열에도 관계없이 같은 결과를 만들어내는 부분적으로 상호 교환이 가능한 생성 시스템의 처리에 적합하다. 체계적인 탐색 과정은 연산자의 많은 순열로부터 같은 노드를 여러 번 만들어낼 수 있다. 이것은 위에 보여진 물 주전자 문제에서도 발생한다.
3. 지식의 표현과 골조 문제
탐색 과정은 트리나 그래프를 따라 이동하는 과정으로 설명되는데, 각 노드는 문제 영역 내에서 하나의 점으로 표기된다. 그러나 어떤 방법으로 개개의 노드를 나타낼 것인가? 체스의 경우, 배열을 사용하여 노드를 나타낼 수 있다. 이때 배열의 각 원소는 해당되는 장기판의 위치에 있는 장기말을 나타낸다. 또 다른 방법은 리스트를 사용하여 나타내는 방법으로 리스트의 각 원소는 해당되는 장기말의 위치를 나타낸다. 물 주전자 문제의 경우 두 개의 물 주전자에 각각 담겨 있는 물의 양을 나타내는 정수의 순서쌍 (a, b) 를 사용하여 각 노드를 표기할 수 있다.
그러나 만약 풀고자 하는 문제가 더욱 복잡하다면 어떠한 문제가 일어나겠는가? 로보트 문제의 경우, 로보트의 탐색 공간 내에서 로보트 스스로를 움직이거나 혹은 다른 물체를 움직이는 노드를 표현하는 방법에 대해 살펴 보자. 현실 세계와 같이 복잡한 분야에서는 표기에 관계된 문제를 세 개의 작은 부분으로 나누어 생각하는 것이 효과적이다 :
- 개개의 물체와 사실은 어떻게 표현되는가?
- 완전한 문제의 상태를 표기하기 위해, 각 물체에 대해 개별적으로 표기된 것들을 결합하는 방법은?
- 탐색 과정 중 발생하는 일련의 문제 상태를 효율적으로 표기할 수 있는 방법은?
예를 들어, 많은 물체로 구성된 로보트 세계의 경우 개개의 물체 상태와 물체간의 관계를 나타내는 사실을 각각 표기할 수 있는 방법이 필요하다. ON(plant, table), UNDER(table, window) 및 IN(table, room) 을 적절히 결합하여 문제의 상태를 완전히 기술할 수 있는 방법을 찾고, 매우 효율적인 방법을 사용하여 일련의 상태를 표기할 방법을 찾아야 한다.
위의 세 가지 문제 중 처음 두 문제는 지식의 표현의 문제라 한다. 비록 지식의 표현이란 문제가 여전히 완전한 풀이를 갖지 못한 어려운 문제이지만, 광범위하게 적용될 수 있는 몇몇 기법들이 개발되었다. 이 기법들 중의 하나는 서술 논리 (predicate logic) 를 기초로 한 것으로써, 제 5 장에서 다루어진다. 또 다른 기법은 지식을 물체의 집합으로 표기된다. 제 7 장에서 이 기법이 소개된다.
세번째 문제는 탐색 과정면에서 볼 때 특히 중요하다. 각 노드가 그 노드를 나타내는 모든 것들의 리스트로 표현된다고 가정하자. 비록 이것이 간단한 방법이라 할지라도, 각 노드에 대한 기술이 매우 길 경우 탐색 과정 동안 발생할 일에 대해 살펴보자. 모든 노드에 대해 각 사실을 한 번씩 표기해야 하기 때문에 메모리가 거의 모두 소모될 것이다. 더구나 이러한 노드를 만들고 변화가 거의 없는 대부분의 사실을 각 노드에 복사하기 위해서 많은 시간이 소모될 것이다. 예를 들어 로보트 문제에서, 모든 노드에 ABOVE(ceiling, floor) 를 기록하기 위해 많은 시간이 소모될 수 있다. 이러한 것은 어떤 사실이 각 노드에서 어떻게 다른지를 알아야 하는 실제 문제를 더욱 어렵게 만든다.
바뀌지 않을 사실 뿐만 아니라 바뀐 사실을 표기하는 전반적인 문제를 골조 문제 (frame problem) 라 한다. 사실을 모두 표기하는 것만이 난제로 대두되는 문제의 분야도 있지만 바뀐 사실을 찾아내는 것조차 어려운 문제로 대두되는 문제의 분야도 있다. 예를 들면 간단한 로보트 문제에서, 창문 아래 있으면서 그 위에 화분을 가지고 있는 탁자가 있다고 가정하자. 방의 중앙으로 탁자를 옮겨 놓으려 한다. 이때 탁자와 함께 화분도 또한 방의 중앙으로 탁자를 옮겨 놓으려 한다. 이때 탁자와 함께 화분도 또한 방의 중앙으로 옮겨졌지만, 창문을 원래의 위치에 있음을 유추할 수 있다.
초기 상태의 기술로부터 시작하여 적용을 적용함에 따라 발생하는 변화를 각 상태의 기술에 반영시키면서 변화된 문제의 상태를 표기한다고 가정하자. 이 방법을 사용하여 각 노드마다 정보를 복사하기 위해 관련된 공간과 시간의 낭비를 해결할 수 있다. 처음으로 후진 탐색해야 할 때가 발생할 때까지 이 방법은 훌륭히 작용한다. 만약 만들어진 모든 변화들을 무시할 수 없다면 (예를 들어 만들어진 변화가 정리를 새로이 첨가함으로 인한 변화와 유사한 것이라면 이 변화는 무시할 수 있다.) 이미 이전에 탐색한 어느 적절한 노드로 후진해야 한다. 그러나 문제 상태의 기술에 이미 만들어진 변화를 만들어지지 않은 것처럼 해야 한다는 것을 어떻게 알 수 있겠는가? 예를 들어 방의 한 가운데로 탁자를 옮긴 후의 변화를 마치 일어나지 않은 것처럼 하기 위해 무엇을 수정해야 하는가? 두 가지 방법을 사용하여 이 문제를 해결한다 :
- 초기 상태의 기술을 전혀 수정하지 않는다. 각 노드마다 이 노드에 대해 만들어진 특별한 변화를 알려 주는 표시를 저장한다. 현재의 상태에 대한 기술을 조사하고, 초기 상태에서 현재의 상태로 가는 경로 위에 있는 모든 노드를 다시 살펴 본다. 이 방법을 사용하면 쉽게 후진할 수 있지만 상태에 대한 기술을 참조하기가 복잡해진다.
- 출발 상태를 적절히 수정하지만, 또한 각 노드마다, 노드를 따라 후진할 경우 이전에 만들어진 변화를 마치 만들어지지 않은 것처럼 하기 위해 행해야 할 일을 알려주는 표시를 기록한다. 후진이 필요할 때마다, 경로를 따라 각 노드를 조사하여 상태의 기술에 표시된 작용을 수행한다.
때때로 위의 해결 방법조차도 불충분할 때가 있다. 예를 들어 로보트 문제에서 탁자는 옮겨지기 전에 창문 아래 있었으며, 옮겨진 후에는 방의 중앙에 있음을 기억해야 한다. 이것은 각 사실의 기술에 이 사실에 참이었던 때를 알려 주는 특별한 표시를 첨가함으로써 처리된다. 이 표시를 상태 변수 (state variable) 라 한다.
그러나, 현실 세계의 문제에 위와 같은 기법을 적용할 경우, 예를 들어 자유의 여신상이 뉴욕에 있던 모든 시대를 알리는 사실들을 분류해야 한다. 이러한 문제는 특히 로보트 문제에서 발생하는 것처럼 분해가 불가능한 문제에서 중요하게 고려되어야 하는데, 이것은 제 8 장에서 다루어질 것이다.
지식의 표현이나 골조 문제는 간단하게 풀이를 얻을 수 있는 종류의 문제가 아니며 특수한 문제와 관련지어 각각을 처리하는 것이 효과적이다. 그러나 지식의 표현과 탐색 과정을 서로 매우 상호 의존적이기 때문에, 이 장에서 탐색 방법을 공부하는 동안 항상 이 문제들을 명심해야 한다.
4. 비교 선택 (Matching)
풀이를 얻을 때까지, 적당한 규칙을 개개의 문제 상태에 적용하여 새로운 상태를 만들어 가는 과정으로 문제를 풀기 위한 탐색 과정으로 설명하였다. 효과적인 탐색을 위해서는, 특별한 경우에 적용될 수 있는 규칙이 여러 개 존재할 때 이 중에서 풀이로 이끌 가능성이 가장 높은 것을 선택하는 방법이 필요하다. 그러나 지금까지 이 방법에 대해서는 언급하지 않았다. 이를 위해 현재 상태와 규칙의 좌측면, 즉 선결 조건을 비교하여 일치하는 것을 선택해야 한다. 규칙을 토대로 한 시스템 (rule-based system) 에서 이 선택 방법은 중요한 위치를 차지한다. 제안된 몇 가지 방법들을 아래에서 소개한다.
(1) 색인화 방법 (Indexing)
적용할 수 있는 규칙을 선택하는 한 가지 방법은, 현재의 상태와 규칙의 선결 조건을 하나씩 비교하면서 현재의 상태와 일치하는 선결 조건을 가진 규칙을 모두 찾아 내는 방법이다. 그러나 이 간단한 방법에는 두 가지 문제점이 존재한다 :
- 주어진 문제를 풀기 위해서, 많은 규칙이 사용될 수 있는데, 탐색 과정의 각 단계보다 이 모든 규칙을 조사하는 것은 극히 비효율적이다.
- 특정한 상태가 규칙의 선결 조건을 만족시킬 수 있는지의 여부가 항상 명백한 것은 아니다.
위의 첫번째 문제를 쉽게 처리할 수 있는 방법이 존재하는 경우도 있다. 규칙들을 모두 조사하는 대신, 현재 상태를 규칙의 색인으로 사용하여, 그것과 즉시 일치하는 규칙을 선택한다. 예를 들어, 2-1 절에서 소개된 체스의 생성 규칙들을 다시 살펴 보자. 그림 6 에 다시 소개되었는데, 적합한 규칙을 즉시 찾기 위해, 장기판의 상태에 매우 큰 수를 색인으로 지정한다. 효율적인 해쉬 함수를 이용하여 얻은 색인의 값으로 규칙을 찾아낼 수 있다. 주어진 장기판의 상태를 나타내는 모든 규칙들이 하나의 동일한 키를 가지고 저장되어 있기 때문에, 이 모든 규칙들이 함께 발견된다. 그러나 이 간단한 색인화 방법은 규칙의 선결 조건이 장기판의 상태와 정확히 일치될 때만 작용하는 결정을 가지고 있다. 따라서 이것에 의한 비교 선택 과정은 쉽고 간단하지만, 일반성이 부족하다. 2-1 절에서 논의된 것처럼 그림 7 에서 보여진 것처럼 좀 더 일반적인 형태로 규칙을 표기하는 것이 효과적이다. 그러나 그렇게 되면 색인화 방법을 사용할 수 없다. 사실상, 규칙을 일반적인 형태로 표기하는 것과 비교 선택 과정을 단순하게 하는 것 사이에는 상호 장ㆍ단점이 있다.
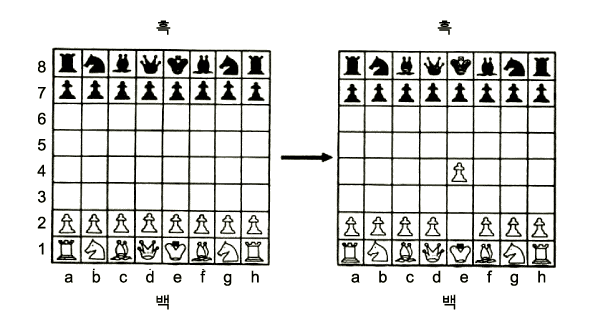
그림 6 체스 말의 올바른 이동
|
백의 말이 (i 열, 2 행) 에 있음 ∧ (i 열, 3 행) 이 비어 있음 ∧ (i 열, 4 행) 이 비어 있음 |
→ |
말을 (i 열, 2 행) 에서 (i 열, 4 행) 으로 이동함 |
그림 7 체스 말의 이동을 표시하는 또 다른 방법
위의 사실은, 술어가 있는 명제를 사용하여 규칙의 선결 조건을 표기할 경우, 색인화 방법을 전혀 사용할 수 없다는 것을 의미하지는 않는다. 예를 들어, 정리 증명에 관한 많은 문제에서, 정리에 포함된 술어가 있는 명제를 규칙의 색인으로 사용하여 특정한 사실을 증명하기에 적합한 모든 규칙을 상당히 빨리 찾아낼 수 있다. 체스의 경우, 장기말과 그것의 위치를 규칙의 색인으로 이용할 수 있다. 색인화 방법의 결점에도 불구하고, 규칙을 토대로 한 시스템의 효율적인 운용을 위해 이 방법이 중요하게 사용된다.
(2) 변수가 있는 비교 선택 방법
때때로, 적합하다고 생각하는 어느 한 규칙을 직접 선택하는 방법보다 여러 규칙 중에서 가장 적합한 것을 선택하는 방법이 비효율적인 경우가 있다. 특정한 규칙과 주어진 문제 상태를 비교하여 이 규칙의 선결 조건이 만족하는지 결정하는 것은 사소한 문제가 아니다. 선결 조건을 특정한 상황으로 정확하게 기술하지 않고, 상황이 가져야 할 성질로 기술할 경우, 색인화 방법에서와 같은 문제가 발생한다. 특정한 상황이 주어진 규칙의 선결 조건과 일치하는지 결정하기 위해서도 중요한 탐색 과정이 요구된다.
|
SON (Mary, John) SON (John, Bill) SON (Bill, Tom) SON (Bill, Joe) DAUGHTER (John, Sue) DAUGHTER (Sue, Judy) |
그림 8 가족 상황에 대한 초기 집합의 예
|
1 SON (x, y) ∧ SON (y, z) → GRANDSON (x, z) 2 DAUGHTER (x, y) ∧ SON (y, z) → GRANDSON (x, z) 3 SON (x, y) ∧ DAUGHTER (y, z) → GRANDDAUGHTER (x, z) |
그림 9 가족 상황을 추론하기 위한 규칙
패턴이 변수를 포함하고 있을 경우, 변수를 일치시키기 위해서 광대한 탐색을 수행해야 한다. 예를 들어 "존 (John) 의 손자는 누구인가?" 라는 질문의 답을 찾아 보자. 이를 풀기 위해 그림 8 에 보여진 데이터 베이스와 그림 9 에 있는 규칙들을 사용한다. 초기 상태는 이 데이터 베이스이며, 목표 상태는 초기 상태에서 주어진 사실 뿐만 아니라 존의 손자가 누구인지를 알려 주는 사실을 포함하고 있는 데이터 베이스이다. X 와 존이 관계가 있다면, 규칙 1 과 규칙 2 를 사용하여 이 사실을 알린다. 그러나 규칙 1 에 대한 선결 조건이 만족하는지 조사하기 위해서는, 특정한 어떤 Z 의 값에 대해 SON (John, y) 와 SON (y, z) 를 만족하는 y 를 하나 찾아야 한다. 이를 위해, 술어를 포함하고 있는 명제 중의 하나를 만족시키는 y 를 찾아, 그것이 다른 하나를 만족시키는지 조사해야 한다. 이는 존의 아들을 모두 찾은 후 이들 중 누가 아들을 가지고 있는지 조사하거나, 아들을 가진 사람을 모두 찾아, 이들 중 누가 존의 아들인지를 조사함으로써 해결될 수 있다. 이 경우, 만약 존의 아들로부터 시작하여 이들 중 누가 아들을 가졌는지 조사한다면, 불필요하게 많은 가능성을 조사하지 않아도 되지만, 술어를 포함하고 있는 명제들 중 어느 것을 먼저 조사해야 하는지를 항상 미리 알 수 있는 것은 아니다. 때때로, 술어를 포함하고 있는 각 명제를 만족시키는 값은 매우 크지만, 이들 모두를 만족시키는 값은 극히 적을 경우가 있다.
앞의 예는 변수를 일치시킬 때 발생하는 두 가지 문제점을 설명해 준다. 첫번째 문제점은 패턴과 상태의 기술간에 일치가 발견되었다는 것 뿐만 아니라, 상태의 기술과 일치하는 패턴을 찾는 과정에서 수행된 바인딩을 기록하여, 규칙을 적용할 때도 이 바인딩이 사용되도록 해야 하는 것이다. 앞의 예에서 비교하여 일치하는 것을 찾는 과정에서 얻은 정보, 즉 규칙 1 의 선결 조건은 x 에 존을, y 에 빌을 그리고 z 에 톰을 바인딩할 때 만족된다는 정보를 규칙을 적용하는 과정에 전달하여, 규칙을 적용할 때 GRANDSON(x, z) 로부터 GRANDSON(John, Tom) 을 얻어낼 수 있도록 한다.
두번째 문제점은 하나의 규칙이 한 가지 이상의 방법으로 현재의 상태와 일치되어 서로 다른 우측면이 여러 개 만들어질 수 잇다는 점이다. 앞의 예에서, 규칙 1 의 z 에 톰과 존을 적용할 수 있는데, z 에 톰을 적용해도, 또는 z 에 존을 적용해도 모두 해를 얻을 수 있다. 그러나 만약 이러한 상태가 풀이를 얻는 경로의 중간 단계에서 나타난다면, 예를 들어 증손자를 찾는 문제를 위한 풀이 경로의 중간 단계에 나타난다면, 어느 바인딩이 더욱 효과적인지 명백하게 즉시 알 수 없는 단점이 있다. 따라서 주어진 상태의 후계 상태가 될 수 있는 상태의 수는 적용될 규칙의 수에 의해 결정되는 것이 아니라 규칙을 적용하는 방법의 수에 의해 결정되는 것임을 명심해야 한다.
(3) 복잡한 근사적인 비교 선택
규칙의 선결 조건이 현재 상태를 명백히 기술하지 않고 대신 필요한 성질만을 규정하는 경우에, 좀 더 복잡한 비교 선택 과정이 필요하다. 이 경우, 일부 성질이 나머지 다른 성질로부터 유추되는 방법을 나타내기 위해서는, 개별적인 규칙의 집합이 사용되어야만 한다.
규칙의 선결 조건을 현재 상태와 근사적으로 일치 시키기 위해서는 복잡한 비교 선택 과정이 필요하다 이것은 흔히, 현실 생활에서 일어나는 상황을 기술할 때 발생한다. 예를 들어, 표기된 물리적인 파동으로부터 이에 대응하는 음성을 얻어내는 음성 이해 프로그램 (speech-understanding program) 에서는 근사적으로 일치되는 규칙을 사용한다. 현실적으로 볼 때, 주위의 소음 등으로, 물리적인 신호가 변질될 수 있고, 또한 개인마다 발음하는 방법에 차이가 있기 때문에, 이상적인 음성을 나타내는 규칙은 현실 세계로부터 들어오는 입력과 근사적으로 일치될 수밖에 없다. 이러한 경우, 일치시킬 때 필요한 선결 조건의 규제를 완화시킴에 따라 일치될 수 있는 규칙의 수가 증가하여, 결과적으로 주된 탐색 과정의 크기가 증가하기 대문에, 근사적인 비교 선택의 처리는 특히 어렵다. 정확한 비교 선택 방법을 이용할 때 어떠한 규칙도 일치되지 않아, 탐색 과정이 결과를 얻지 못하고 중단되어야 하는 상황에서 근사적인 비교 선택 방법을 효과적으로 작용한다.
일부 문제의 경우, 거의 모든 상태의 전이가 규칙이 문제 상태와 일치할 때 발생한다. 일단 상태의 전이가 일어나면, 규칙을 거의 적용하지 않고도 나머지 탐색 과정을 쉽게 수행할 수 있다. 예를 들어, 이것은 ELIZA 에서 발생하는데, Rogerian 치료 학자의 행동을 시뮬레이션하는 인공 지능 프로그램이다. ELIZA 와 사용자 간의 대화의 한 예가 그림 10 에 소개되었다. 영어와 심리학에 대한 ELIZA 의 지식을 간단한 규칙들로 코드화 할 수 있는데, 이 규칙들의 예가 그림 9-4 에 보여진다. ELIZA 는 사용자의 마지막 문장과 좌측면이 일치하는 규칙을 찾아 그 규칙의 우측면을 사용하여 질문에 응답한다. 규칙들이 핵심이 되는 단어에 의해 색인화 되어 있기 때문에 사실상 소수의 규칙만이 특정한 문장과 일치된다. 좌측면이 없는 규칙은 어느 곳에든지 적용될 수 있다. 현재의 상태가 다른 어떤 규칙과도 일치하지 않을 때 이 규칙을 사용하여, "저에게 그것에 대해 말해 주시오" 와 같은 응답을 만든다. 이 경우, 근사적인 비교 선택의 형태가 규칙 자체에 의해서도 발생될 수 있음에 주의해야 한다. 패턴은 문장내에서 특정한 단어만 이용하기 때문에 전체 문장과 일치할 필요는 없다. 따라서 하나의 규칙에 의해 여러 개의 문장들이 비교 일치될 수 있는데, 이때 영어 문장의 문법적인 복잡성은 무시한다. 이것은 ELIZA 의 강력한 장점, 즉 거의 대부분 합리적인 응답을 할 수 있는 능력뿐만 아니라, 매우 결정적인 단점, 즉 피상적인 이해와 완전히 빗나간 응답을 할 수 있는 능력도 또한 설명해 준다. 근사적 비교 선택 방법을 사용할 경우 위의 두 가지 결과가 모두 쉽게 발생할 수 있다.
|
Men are all alike. IN WHAT WAY They're always bugging us about something or other. CAN YOU THINK OF A SPECIFIC EXAMPLE Well, my boyfriend made me come here. YOUR BOYFRIEND MADE YOU COME HERE He says I'm depressed much of the time. I AM SORRY TO HEAR YOU ARE DEPRESSED It's true. I am unhappy. DO YOU THINK COMING HERE WILL HELP YOU NOT TO BE UNHAPPY I need some help, that much seems certain. WHAT WOULD IT MEAN TO YOU IF YOU GOT SOME HELP Perhaps I could learn to get along with my mother. TELL ME MORE ABOUT YOUR FAMILY . . . |
그림 10 ELIZA 와 사용자 간의 대화
비교 선택 과정이 그다지 복잡하지 않은 것처럼 가정하여, 앞 절에서 언급된 골조 문제 (frame problem) 를 살펴 보자. 골조 문제를 처리하는 방법은 각 노드마다, 상태에 대한 기술을 모두 기록하지 않는 대신 이전 노드로부터의 변화만을 기록하는 것이다. 만약 이렇게 한다면 원하는 노드를 찾을 때까지, 한 노드로부터 그것의 전임 노드를 따라 후진하면서 일치되는 것을 찾아야 한다.
(4) 비교 선택 결과의 여과
비교 선택 과정의 결과, 좌측면이 현재 상태와 일치하는 규칙들의 목록이 얻어진다. 탐색 방법을 규칙이 적용되는 순서를 결정하는 작업을 하는데, 이 작업을 비교 선택과정에서 함께 처리할 수 있다. 비교 선택 과정 중 이 단계를 충돌 해결의 단계라 한다.
예를 들어, 시스템의 일부 규칙이 나머지 다른 규칙에 의해 나타내진 상황의 특별한 경우를 처리한다고 가정하자. 이렇게 특별성을 띤 규칙은 일반성을 띤 규칙보다 높은 우선 순위를 가지고 있다. 물 주전자 문제를 다시 살펴 보자. 이 문제에서 목표 상태가 주전자 중의 하나에 n 갈론의 물을 담아 다른 하나의 물 주전자에 n 갈론의 물을 옮겨 붓는 것이라고 한다면, 그림 2-3 의 규칙에 다음 두 가지 규칙을 첨가해야 한다 :
11 (0, 2) → (2, 0) 2 갈론의 물을 4 갈론 들이 물 주전자에 옮겨 붓는다.
12 (x, 2 + x > 0) → (0, 2) 4 갈론 들이 주전자를 비운다.
이 새로운 규칙을 이전의 규칙보다 특별한 경우이다. (0, 2) 는 (X, Y | Y > 0) 보다 좀더 한정된 규정이다 [규칙 6 의 선결 조건]. 이와 같이 특수한 규칙을 사용하는 목적은 숙달된 문제 풀이자로 하여금 탐색 과정을 수행하지 않고 직접 문제를 풀기 위해 이러한 종류의 지식을 이용하도록 하기 위해서이다. 그러나 일치된 규칙을 찾기 위해 이용 가능한 규칙을 모두 조사하는 기법을 사용한다면, 특수 용도의 규칙을 첨가함으로써 탐색을 간소화시키기 보다는 탐색의 증가를 초래한다. 이러한 상황을 방지하기 위해, 일반성이 있는 규칙과 특수성이 있는 규칙을 구별하여, 특수성이 있는 규칙을 택하는 비교 선택 과정이 사용된다. 비교 선택 과정에서 한 규칙이 다른 규칙보다 더욱 일반성을 띤다는 것을 결정하기 위해 다음과 같은 간단한 몇 가지 방법이 사용된다 :
- 만약 규칙 A 의 선결 조건이 규칙 B 의 모든 선결 조건 및 그 외의 다른 선결 조건을 포함하고 있을 때, 규칙 A 가 규칙 B 보다 일반성을 띤다고 한다.
- 규칙 A 의 선결 조건과 규칙 B 의 선결 조건이 단지 규칙 B 의 선결 조건에서 상수로 나타나는 것이 규칙 A 의 선결 조건에서 변수로 나타나는 것 외에는 모두 같을 때 규칙 A 가 규칙 B 보다 일반성을 띤다고 한다.
비교 선택 과정이 탐색 기법에 부가된 점을 덜어 주는 또 하나의 방법은 비교 선택될 대상의 중요성에 따라 그것들에 순서를 정해 주는 것이다. 여기에는 여러 가지 방법이 있다. 응답을 위한 규칙을 찾기 위해 사용자의 문장과 패턴을 일치시키는 ELIZA 를 살펴 보자. 입력된 문장에는 ELIZA 가 알고 있는 핵심 단어가 여러 개 포함되어 있을 수 잇다. 만약 그렇다면, ELIZA 는 핵심 단어의 중요성에 대한 정보를 사용하여 수행할 핵심 단어를 선택한다. 패턴 비교 선택 과정은 가장 높은 우선 순위를 가진 핵심 단어를 찾아낸다.
우선 순위가 있는 비교 선택의 또 다른 형태는 현재 상태와 일치될 수 있는 것의 위치에 대한 함수로 나타낼 수 있다. 예를 들어 인간의 단기간의 기억 (human short-term memory : STM) 의 행동에 대한 모형을 만들고자 할 때, STM 의 현재 내용과 일치하는 규칙은 외부에 결과를 출력하거나, 장기간의 메모리에 내용을 기록시키기 위해 사용된다. 비교 선택 과정은 가장 최근에 STM 에 들어온 입력과 일치하는 규칙을 찾으려 하고, 만약 일치하는 규칙을 찾지 못하면, 이전에 STM 에 들어온 입력과 일치하는 규칙을 찾는다.
비교 선택 과정과 탐색 과정의 구조에 따라 이 두 개가 상호 작용하는 방법이 결정된다. 그러나 위에서 언급한 상황의 경우, 비교 선택 과정은 그것의 기본적인 작업을 수행하는 과정에서 탐색 과정에 사용될 정보를 항상 이용할 수 있는데, 이를 위해 정보를 상호 교환하는 것이 좋다.
규칙을 토대로 한 시스템에서 비교 선택 과정이 간단하지 않다면 더욱 많은 탐색이 요구된다. 문제 풀이의 초기 단계에서 사용될 수 있는 탐색 과정이 비교 선택 과정에서도 유용하게 사용될 수 있다. 물론, 최종적으로는 탐색의 순환적인 사용이 직접적인 비교 선택 과정 내에서 끝나야만 한다.
5. 경험적 방법에 사용되는 평가 함수
2-1-2 절에서 경험적 방법은 비록 그릇된 방향으로 문제 풀이 과정을 유도할 수 있지만, 문제에 대한 풀이를 발견하는데 도움이 되는 기법으로 정의되었으며 일반적으로 적용될 수 있는 경험적 방법과 특정한 문제의 풀이에 적합한 특수한 지식을 나타내는 경험적 방법이 있다. 6 절에서 설명될 문제 풀이 방법은 범용 경험적 방법이지만 주어진 특수한 분야와 관련된 적절한 특수 용도의 경험적 방법과 함께 사용되어, 특수 분야에도 적용될 수 있다.
다음 두 가지 방법을 사용하여 영역 특성에 따른 경험적 방법의 정보를, 규칙을 토대로 한 탐색 과정과 결합할 수 있다.
- 규칙을 이용한다. 예를 들면 체스 시스템에 대한 규칙은 말의 합당한 움직임 뿐만 아니라 가능한 움직임도 나타낼 수 있는데, 이것은 규칙 작성자에 의해 결정된다.
- 각 문제 상태의 가치를 평가하여, 그 문제 상태가 얼마나 적합한지를 결정하는 평가 함수를 이용한다.
경험적 방법에 사용되는 평가 함수는 문제의 상태에 대한 기술이 얼마나 적합한 것인지를 의미하는 값을 계산한다. 탐색 과정에 나타나는 각 노드에 대해, 이 노드가 풀이를 이끄는 경로상에 있을 확률의 추정치를 주는 경험적 방법에 사용되는 평가 함수를 사용하여 문제 상태의 어떤 면을 조사해야 할지, 그리고 이것의 가치를 어떻게 평가할지 및 이것에 주어진 가중값을 얻을 수 있다.
잘 만들어진 경험적 방법에 사용되는 평가 함수는 효과적으로 탐색 과정을 풀이로 유도하는 중요한 역할을 한다. 경로의 적합성 여부에 대한 추정값을 얻고자 할 때, 매우 간단한 평가 함수를 사용해도 상당히 좋은 추정값을 얻을 수 있는 경우도 있지만 좀 더 복잡한 평가 함수를 사용해야 할 경우도 있다. 그림 11 에 몇 가지 문제를 예로 들어, 경험적 방법에 사용되는 간단한 평가 함수를 소개하였다. 평가 함수의 값이 클수록 효과적일 경우 (예, 체스, 8-퍼즐, 삼목놀이) 도 있고, 평가 함수의 값이 작을수록 유리한 경우 (예, 세일즈 맨의 방문 문제) 도 있음을 명심하라. 일반적으로 함수를 기술하는 방법은 중요하지 않으며, 함수값을 사용하는 프로그램을 경우에 따라 함수값의 최소화를 시도할 수도 있고, 함수값의 최대화를 시도할 수도 있다.
|
체스 8-퍼즐 세일즈 맨의 방문 문제 삼목 놀이 |
적에 대한 자기 편의 남은 말들의 유리한 점 올바른 위치에 있는 타일들의 수 방문한 거리의 합
이길 수 잇고, 이미 하나가 놓여 있는 행에 두 개가 놓인 경우에는 더하기 2 |
그림 11 경험적 방법에 사용되는 간단한 평가 함수들의 예
경험적 방법에 사용되는 평가 함수의 목적은, 이용 가능한 경로가 두 개 이상 존재할 때, 먼저 조사할 경로를 결정해 줌으로써, 탐색 과정을 가장 효율적인 방향으로 유도하는 것이다. 경험적 방법에 사용되는 평가 함수가 탐색 트리 (혹은 그래프) 내의 각 노드의 가치를 정확히 평가하면 할수록 풀이 과정은 더욱 더 명백해진다. 극단적으로 경험적 방법에 사용되는 평가 함수를 잘 작성하면 어떤 탐색도 수행하지 않고 직접 풀이를 찾을 수도 있다. 그러나 많은 문제의 경우, 그러한 평가 함수를 평가하는데 소요되는 비용이 탐색 과정에서 절감된 노력을 능가할 수 있기 때문에, 결국 풀고자 하는 노드로부터 끝까지 탐색을 수행하여, 그것이 적당한 풀이를 유도할 수 있을지 결정함으로써, 완전한 평가 함수를 계산할 수 있다. 일반적으로 경험적 방법에 사용되는 평가 함수값의 계산에 소요되는 비용과 그 평가 함수에 의해 얻어진 탐색 시간의 절감은 각각 장ㆍ단점을 가지고 있다.
경험적 방법에 사용되는 평가 함수가 기본적인 탐색 방법에서 차지하는 역할을 각 탐색 방법을 소개할 때 논의될 것이다.
6. 불완전 방법 (Weak Methods)
경험적 탐색 방법은 어려운 문제에 대한 풀이를 얻을 수 있는 매우 강력한 방법이다. 이러한 탐색을 제어하기 위해 사용되는 방법은 특정한 문제를 풀 때 그 탐색 방법이라 불리우는 다음과 같은 범용 제어 방법을 소개한다.
- 해답의 생성과 테스트 방법 (Generate-and-Test)
- 언덕 오르기 방법 (Hill Climbing)
- 나비 우선 탐색 방법 (Breadth-first Search)
- 최적 우선 탐색 방법 (Best-first Search)
- 문제 축소 방법 (Problem Reduction)
- 제한 조건의 만족 방법 (Constraint Satisfaction)
- 방법-목적 분석 방법 (Means-ends Analysis)
특정한 문제에 대한 제어 방법의 선택은 앞 장에서 논의한 문제의 특성에 의해 결정된다. 이 장의 서두에서 지적된 것처럼 모든 탐색 과정은 문제 그래프의 트래버셜로 설명된다. 고려할 가장 간단한 종류의 그래프는 OR 그래프이다. 물 주전자 문제의 풀이 방법을 나타내는 OR 그래프가 그림 5 에 소개되었다. 각 노드에 대해, 이 노드가 나타내는 상태로부터 만들어질 수 있는 여러 움직임을 나타내는 링크를 얻을 수 있는데, 이 링크에 의해 연결된 노드를 링크가 시작되는 노드의 후계 노드라 부른다. 문제의 풀이를 찾기 위해, 그래프 상에서 초기 상태를 나타내는 노드로부터 출발하여, 목표 상태를 나타내는 노드를 찾을 때까지, 각 노드의 후계 노드를 따라가면서 풀이의 경로를 찾는다. 앞으로 공부할 절 중 처음 다섯 개의 절은 OR 그래프의 트래버셜 방법을 설명한다.
그러나 일부 문제의 경우, 하나의 링크가 여러 후계 노드를 지적하는 그래프를 사용하여 풀이를 찾는 것이 효과적인데, 이러한 그래프를 AND-OR 그래프라 하며, 탐색 알고리즘이 소개된 (6) 절에서 논의될 것이다.
경험적 방법이라는 범용 방법이 어려운 문제를 푸는 만병 통치약이 아님을 명심해야 한다. 그러나 이 방법은 주어진 문제에 대해 필요한 특정한 지식을 구조화하고 이용할 수 있는 기틀을 만들어 준다.
(1) 해답의 생성과 테스트 방법 (Generate-and-Test)
해답의 생성과 테스트 방법은 거론될 가장 간단한 방법으로써, 이것의 수행 과정은 다음과 같다 :
- 가능한 해답을 만들어라. 이것은 문제에 따라, 문제 영역 내에서 특정한 상태를 찾는 것을 의미할 수도 있고, 출발 상태로부터의 경로를 만들어내는 것을 의미할 수도 있다.
- 선택한 상태나 혹은 선택된 경로의 최종 상태를 적절한 목표 상태와 비교하면서 이것이 실제 원하는 해답이 되는지 조사하라.
- 해답이 발견되면 중지하라.
해답이 발견되지 않았다면 단계 1 로 돌아가라.
체계적인 방법을 사용하여 가능한 해답을 만든다면, 해답이 존재할 경우, 위 과정에 의해 반드시 해답을 얻을 수 있다. 그러나 주어진 문제가 매우 큰 문제일 경우, 이것을 수행하기 위해서는 긴 시간이 요구될 것이다.
해답의 생성과 테스트 알고리즘은 깊이 우선 탐색의 일종이며, 이 방법의 체계적인 형태에서는 문제 영역을 모두 탐색한다. 물론 해답을 임의로 만들어 내면서 해답의 생성과 테스트 방법을 수행할 수 있지만, 이렇게 하면 풀이를 찾지 못할 경우도 발생한다. 이에 대한 예로 대영 박물관 알고리즘이 알려져 있다. 이 알고리즘을 살펴보자. 많은 원숭이들에게 타자기를 주어 마음대로 두드리게 하면 이로부터 얻은 종이의 내용이 언젠가는 박물관에 소장된 모든 책들의 내용과 일치할 경우가 발생한다. 체계적으로 탐색 과정을 수행하는 현실 세계에서는 풀이로 이끌 가능성이 적은 경로는 탐색하지 않는데, 이 가능성의 평가는 5 절에서 논의된 평가 함수에 의해 행해진다.
후진이 허용된 깊이 우선 탐색 트리를 사용하여 체계적인 해답의 생성과 테스트 방법을 쉽게 구현할 수 있다. 그러나 트리를 탐색하는 과정에서 여러 번 나타나는 상태가 존재한다면, 위에서 소개된 과정을 그래프를 탐색하기에 적합하도록 수정하는 것이 더욱 효율적이다.
간단한 문제의 경우, 해답의 생성과 테스트 방법을 사용하여 문제 영역을 모두 조사하는 것도 합리적인 방법이다. 예를 들어 네 개의 정육면체로 이루어진 퍼즐을 생각해보자. 이때 정육면체의 각 면은 네 가지 색깔 중의 하나로 칠해져 있다. 정육면체를 하나의 열로 배열하는데, 그 열의 네 면에 각 색깔이 모두 보여지도록 정육면체를 배열하고자 한다. 모든 가능성을 체계적으로 모두 조사함으로써 그런 배열을 찾아낼 수 있다. 이것은 또한 독학적 해답의 생성과 테스트 방법을 사용하여 빨리 찾아낼 수 있다. 네 개의 상자를 한 줄로 늘어 놓을 때, 예를 들어, 빨간 면이 다른 색깔의 면보다 많다고 하자. 따라서 빨간 면을 가진 상자를 놓을 때 보이는 쪽에 가능한 한 이 빨간 면들이 나타나지 않도록 다음 상자의 면과 접하게 하는 것이 효율적이다.
그러나, 이보다 어려운 문제의 경우, 경험적 해답의 생성과 테스트 방법은 비효율적인 기법이지만 탐색할 공간을 한정하는 다른 기법과 함께 사용하면, 매우 효과적일 수 있다. 예를 들어 지금까지 작성된 가장 성공적인 인공 지능 프로그램의 하나는 DENDRAL 로서 질량 스펙트럼과 핵 자기 공명 (Nuclear Magnetic Resonance : NMR) 자료를 사용하여, 유기체의 성분 구조를 추론하는 프로그램이다. 이것은 계획 (planning) 에 의한 해답의 생성과 테스트라 불리우는 기법을 사용하는데, 이 기법에서 제한 조건의 만족 방법을 사용하는 계획 과정은 허용된 구조와 금지된 구조의 목록을 만든다. 해답의 생성과 테스트 방법을 상당히 제한된 구조들만을 조사하기 위해 이 목록을 사용한다.
계획 방법과 해답의 생성과 테스트 방법을 결합하여 사용하는 것처럼, 서로 다른 문제 풀이 방법들을 결합하여 개개 풀이 방법의 한계성을 극복할 수 있다. 계획 방법의 가장 큰 결점은 피드백이 불가능하기 때문에, 다소 부정확한 해를 만들 수 있다는 점이다. 그러나 해답의 생성과 테스트 방법에서 조사될 풀이의 목록을 만드는데 이것을 이용한다면, 부정확하다는 결점은 문제시되지 않는다. 또한 간단한 해답의 생성과 테스트 기법에서 발생하는 실행 시간의 급증 문제를 적절한 계획을 사용하여 피할 수 있다.
(2) 언덕 오르기 방법 (Hill Climbing)
언덕 오르기 방법은 탐색 공간 내에서 움직일 방향을 결정하기 위해 피드백을 사용한 해답의 생성과 테스트 방법의 한 변형이다. 순수한 해답의 생성과 테스트 방법에서 테스트 함수는 예, 아니오의 응답만을 하지만, 이것을 주어진 상태가 목표 상태에 얼마나 가까운지를 추정할 수 있는 경험적 방법에 사용되는 평가 함수로 개선하여 아래 과정에서 보여진 것처럼 사용할 수 있다. 이 방법은 풀이에 대한 조사가 수행됨과 동시에 경험적 방법에 사용되는 평가 함수의 계산이 수행될 수 있기 때문에 매우 효과적이다. 언덕 오르기 방법의 프로시쥬어는 다음과 같다 :
1. 해답의 생성과 테스트 방법에서와 같은 방법으로 처음에는 임의로 해답을 만들어라. 이렇게 만들어진 해답이 주어진 문제에 맞는 원하는 해답이면 중단하고, 아니면 다음 과정을 계속 수행하라.
2. 이 해답에 적절한 규칙을 적용하여 새로운 해답을 만들어라. 여러 개의 새로운 해답이 만들어질 수 있다.
3. 새로 만들어진 각각의 해답에 대해 다음을 수행하라.
1) 테스트 함수에 새로이 얻은 해답을 넣어, 만약 원하는 해답이라면 중단하라.
2) 원하는 해답이 아니라면, 조사된 해답 중에서 새로 만든 해답과 가장 가까운 것이 존재하는지 조사하라. 만약 존재한다면 이 해답을 기억하고 그렇지 않으면 무시하라.
4. 위에서 찾은 최적의 해답을 택해 다음에 제안될 해답으로 사용하라. 이 단계는 가장 빨리 목표로 유도할 가능성이 높은 방향으로 문제 영역을 탐색케 하는 단계이다.
5. 단계 2 로 돌아가라.
네 개의 상자로 이루어진 퍼즐 문제를 다시 예로 들어 언덕 오르기 과정의 작용 방법을 살펴 보자. 이 문제를 풀기 위해, 먼저 상자의 특정한 배치가 문제의 해답과 얼마나 가까운지를 나타내는 평가 함수를 정의해야 한다. 네 면의 각각에 있는 서로 다른 색깔 수의 합으로 경험적 방법에 사용되는 평가 함수를 정의할 수 있다. 이 퍼즐에 대한 풀이에서는 평가 함수가 16 의 값을 가질 것이다. 다음은 상자의 배치를 변형시키는 방법을 말하는 규칙을 정의해야 하는데, 사실상 이 문제에서는 하나의 규칙으로 충분하다. 이 규칙은 상자 하나를 선택하여 어느 한 방향으로 90° 회전시키는 것이다. 이것이 정의되면, 다음 단계는 초기 배치를 만드는 것으로써, 임의로 만들 수도 있고, 앞 절에서 언급된 경험적 방법에 사용되는 평가 함수를 이용하여 만들 수도 있다. 지금부터 언덕 오르기를 시작해 보자. 네 개의 상자 모두를 가능한 방향으로 회전시키면서, 원하는 풀이와 가장 가까운 배치를 찾는다. 그러나 이 방법을 사용할 경우 매 단계마다 매우 많은 테스트의 수행이 요구되지만, 사실상 허용 가능한 움직임을 모두 사용할 필요가 없기 때문에, 이들 중 일부만을 조사하면 된다. 따라서 상자를 한 개 선택하고, 그것을 회전시키면서 문제의 목표 상태와 가까워지는 지를 조사한다. 만약 그런 회전이 존재한다면, 그 회전을 수행하고, 다음 과정을 수행한다. 만약 그렇지 않다면 나머지 다른 상자 중에서 하나를 택해 회전시켜 본다. 그러나 원하는 목표 상태로 이끌 수 있는 회전이 하나도 존재하지 않는다면, 이를 어떻게 처리하느냐의 문제가 제기된다.
언덕 오르기 방법에서는 목표 상태로 접근하는 방향으로는 상태를 변화시킬 수 없는 경우가 발생하는데, 경험적 평가 함수의 값이 극대값이나 평원 혹은 산등성이에 도착했을 때 이러한 상태가 발생한다.
- 극대값 (local maximum) 은 인접한 근처의 모든 상태들보다는 원하는 목표 상태에 가깝지만, 멀리 떨어져 있는 다른 모든 상태들보다는 목표 상태에 가깝지 못할 경우이다.
- 평원 (plateau) 은 인접한 상태들이 모두 같은 값을 갖는 탐색 공간의 평탄한 지역이다. 평원에서는 국부적 비교를 이용하여, 움직일 최적 방향을 결정하는 것은 불가능하다.
- 산등성이 (ridge) 는 주위 지역보다는 높지만, 하나의 움직임만으로는 어느 일정한 방향으로 탐색을 계속 수행할 수 없는 탐색 공간의 영역이다.
위의 문제를 확실히 해결한다고 할 수는 없지만, 이를 처리하기 위해 몇 가지 방법이 사용된다.
- 이전에 탐색되었던, 어떤 노드를 후진하여 다른 방향으로의 탐색을 시도한다. 이 방법은 특히 각 노드마다, 이전에 택했던 방향만큼 가능성이 있는 또 다른 방향이 존재할 경우 적절한 해결책이 된다. 이 방법을 구현하기 위해서는 탐색 도중 선택될 가능성이 있는 경로들의 목록을 만들어 만약 택한 경로가 부적합한 결과를 초래할 경우, 목록에 있는 경로 중의 하나로 되돌아 간다. 이 방법은 극대값을 상당히 효율적으로 처리한다.
- 탐색 공간의 다른 새로운 지역으로 가기 위해 어떤 한 방향으로 커다란 점프를 한다. 이 방법은 특별히 평원의 처리에 효과적이다. 이용 가능한 규칙을 적용할 때 상태의 변화 범위가 매우 적다면, 이 규칙들을 같은 방향으로 여러 번 적용하라.
- 조사하기에 앞서 둘 이상의 규칙을 적용하여 동시에 여러 방향으로 움직이도록 한다. 이는 특히 산등성이의 처리에 적합하다.
좋은 평가 함수를 사용한다고 해서 언덕 오르기 방법이 항상 효과적인 것은 아니다. 해답으로부터 멀어짐에 따라, 경험적 지식에 사용되는 평가 함수의 값이 갑자기 작아지는 문제에 이 방법을 사용하는 것은 부적합한데, 이는 일종의 역치 효과 (threshold 효과) 가 존재하는 경우이다. 언덕 오르기 방법은 2-1-2 절에서 설명된 최단 이웃 알고리즘과 같은 다른 국부적인 방법을 함께 사용되어, 탐색 시간의 폭발적인 급증 문제를 해결할 수 있는 장점이 있는 반면, 효율적이지 못할 경우도 있다는 결점이 있다. 방대하고 비 구조화된 문제에서 언덕 오르기 방법은 매우 비효율적이다.
(3) 나비 우선 탐색 방법 (Breadth-First Search)
해답의 생성과 테스트 방법 및 언덕 오르기 방법은 깊이 우선 탐색 방법의 일종이다. 그러한 방법은 구현이 쉽고, 매우 빨리 효율적인 해답을 얻을 수 있지만, 불필요한 경로를 탐색하기 위해 많은 시간을 소비하는 경우가 빈번히 발생한다. 나비 우선 탐색은 다음 레벨의 노드를 조사하기 앞서 트리의 같은 레벨이 있는 모든 노드를 먼저 조사하는 방법이다. 이 방법은 트리 탐색 뿐만 아니라 그래프 탐색으로 변환시켜 수행할 수 있다.
트리가 유한 개의 가지를 가지고 있고, 해답이 존재한다면, 나비 우선 탐색 방법을 사용하여 해답을 반드시 찾을 수 있는데, 이것은 쉽게 증명할 수 있다. 만약 해답이 존재한다면, 출발 상태로부터 목표 상태를 연결하는, 유한 길이 (편의상 N 이라 하자.) 를 가진 경로가 존재한다. 나비 우선 탐색 과정은 길이가 1 인 경로를 모두 탐색하는데, 트리에는 길이 1 인 경로가 유한개 존재한다. 다음 단계에서, 유한개 존재하는 길이 2 의 경로를 조사한다. 길이 N 의 경로를 모두 조사하여 풀이를 찾을 때까지 이 과정을 계속 수행한다. 풀이를 찾기 위해 나비 우선 탐색 방법을 사용할 경우, 임의의 경로를 찾는 것이 아니라 최단 거리를 가진 경로를 찾게 되는 것이다. 물론, 다른 가지보다 부적당한 가지가 존재한다면 (예를 들면, 탐색하기에 너무 많은 비용을 요구하는 가지), 이렇게 얻은 경로는 원하는 최적 경로가 아니다.
나비 우선 탐색 방법에는 다음 세 가지 문제점이 존재한다 :
1. 많은 기억 장소가 필요하다. 트리의 각 레벨의 노드 수는 레벨 수에 따라 지수 함수에 비례하며 증가하는데, 모든 노드가 동시에 기록되어야 한다.
2. 조사해야 할 노드 수가 경로의 길이에 대해 지수 함수적으로 비례하기 때문에, 해의 최단 경로가 매우 길 경우, 특히 많은 작업의 수행이 요구된다.
3. 부적합하거나 불필요한 연산자는 조사해야 할 노드 수를 크게 증가시킨다.
풀이로 이끄는 경로는 많이 있지만, 이들 경로의 길이가 매우 긴 문제에 나비 우선 탐색 방법을 사용하는 것은 비효율적이다. 이러한 문제에는 깊이 우선 탐색 방법을 사용하는 것이 더욱 효과적이다.
(4) 최적 우선 탐색 방법 (Best-First Search) : OR 그래프
깊이 우선 탐색 방법과 나비 우선 탐색 방법의 장점만을 취해 하나로 만든 방법이 최적 우선 탐색 방법 (Best-First Search) 이다. 최적 우선 탐색의 매 단계마다, 경험적 지식에 사용되는 적절한 평가 함수를 적용하여, 지금까지 만들어진 노드 중 풀이로 이끌 가능성이 가장 높은 노드를 택한다. 후계 노드를 만들기 위해 규칙을 이용하여 선택된 노드를 전개, 확장한다. 만약 이들 후계 노드 중에 원하는 목표 상태가 포함되어 있다면 수행을 중단하고, 그렇지 않다면 새로 만들어진 후계 노드를 지금까지 만들어진 노드로 구성된 집합에 첨가한다. 다시 되풀이로 이끌 가능성이 가장 높은 노드를 찾아 최적 우선 탐색을 계속 수행한다. 풀이를 얻을 가능성이 가장 높은 방향으로 탐색해 가기 위해 깊이 우선 탐색 방법을 사용한다. 그러나 원하는 목표 풀이를 찾지 못하면, 이전에는 부적당한 것으로 간주되어 무시되었지만, 현재는 가장 유망한 것으로 평가되는 경로를 찾아 탐색을 계속한다.
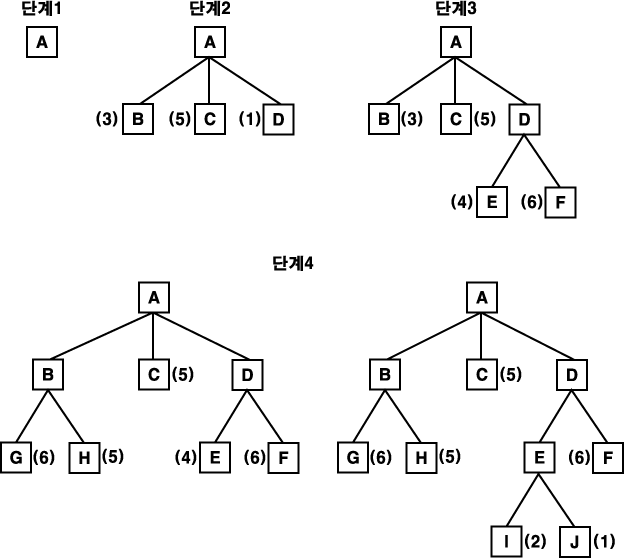
그림 12 최적 우선 탐색
그림 12 는 최적 우선 탐색의 초기 상태를 나타낸다. 초기 상태는 하나의 노드로 구성되어 있는데, 이 노드를 확장 전개하여 세 개의 새로운 노드를 만든다. 다음 단계에서 수행될 노드를 택하기 위해, 새로이 만들어진 노드에 비용을 계산하는 평가 함수를 적용한다. 이로부터 노드 D 가 풀이를 이끌 가능성이 가장 높은 노드로 나타났기 때문에, 이것을 확장 전개하여 두 개의 후계 노드 E 와 F 를 만들어 이 두 개의 노드에 다시 경험적 방법에 사용되는 평가 함수를 적용한다. 지금까지 조사한 A-D-E/F 경로보다 A-B 경로가 더 유망한 것으로 나타났기 때문에, B 를 확장 전개하여 G 와 H 라는 후계 노드를 만든다. 그러나 새로운 G 와 H 를 평가하여 이 경로가 다른 경로들 보다 비효율적인 것으로 판단되었기 때문에 D 와 E 를 지나는 경로를 다시 조사한다. E 를 확장하여 I 와 J 를 만들고, 다음 단계에서, 가장 유망한 것으로 평가된 노드 J 를 확장 전개한다. 원하는 목표 상태를 얻을 때까지 이 과정을 계속 수행한다.
앞의 예에서는 비록 트리의 최적 우선 탐색 방법을 설명하였지만, 중복되는 경로의 탐색을 피하기 위해 그래프를 탐색하는 것이 효과적일 수 있다. A* 알고리즘은 문제 그래프의 최적 우선 탐색을 구현한 방법으로써 매우 효과적인 알고리즘이다. 이제, A* 알고리즘에 대해 살펴 보자.
각 노드가 문제 공간 내의 어느 한 상태를 나타내는 방향성 그래프를 탐색하면서 알고리즘이 수행된다. 각 노드에는 다음과 같은 내용이 포함되어 있다 : 문제 상태에 대한 기술, 이 노드가 풀이로 이끌 가능성을 알리는 표시, 이 노드를 후계 노드로 만들었던 최적 노드를 지적하는 부모 링크 (parent link) 이 노드의 후계 노드를 나타내는 목록, 부모 링크는 일단 원하는 목표 상태를 찾게 되었을 때, 이 목표 상태를 이끈 경로를 되찾기 위해 사용된다. 만약 더 효율적인 경로가 이미 존재하는 노드에서 발견된다면, 이것의 후계 노드를 탐색하기 위해 후계 노드의 목록을 사용한다.
A* 알고리즘을 수행하기 위해 노드에 대한 두 가지 목록이 필요하다.
- OPEN : 생성된 노드 중, 독학적 방법에 사용되는 평가 함수는 이미 적용되었지만 아직 조사되지 않은 노드들의 목록으로써, 평가 함수의 값이 가장 좋은 노드가 가장 높은 우선 순위를 가진 우선 순위 큐 (prionity queue) 이다. 우선 순위의 큐를 처리하는 표준적인 기법을 사용하여 이 목록을 사용한다.
- CLOSED : 이미 조사된 노드의 목록
또한 생성된 각 노드의 장점을 평가하기 위해 경험적 지식에 사용되는 평가 함수가 필요하다. 이 함수를 이용하여 알고리즘은 좀 더 좋은 경로를 먼저 탐색할 수 있다. f' (노드의 참값을 주는 함수 f 의 근사 함수) 라 불리우는 이 함수는 g 와 h' 라는 두 함수의 합으로 정의된다. 함수 g 는 출발 상태로부터 현재 노드까지 오는데 소요된 비용을 나타낸 것으로써 추정값이 아니라, 최적 경로를 따라 규칙을 적용하며 노드를 만들 때 소요된 비용의 합이다. 함수 h' 는 현재 노드로부터 목표 상태로 갈 때 필요한 것으로 추정되는 비용의 추정값으로써, 이를 위해 문제 영역에 대한 지식이 이용된다. 함수 f' 의 출발 상태로부터 현재 만들어진 노드를 지나 목표 상태로 갈 때 필요한 비용의 추정값이다. 만약 어떤 노드를 만드는 경로가 한 개 이상 존재한다면, 알고리즘은 이 중 가장 적절한 경로를 선택해 기록한다. g 와 h' 를 더해야 하기 때문에, h' 는 노드의 유용성 (좋은 노드가 높은 값을 얻음) 을 측정하는 것이 아니라 그 노드로부터 목표 상태로 갈 때 필요한 비용 (적합한 노드는 작은 값, 부적합한 노드는 큰 값을 얻는다) 측정해야 함을 명심하라. 또한 g 는 음이 아닌 값이어야 한다. 만약 그렇지 않다면, 탐색하는 그래프의 경로에 사이클이 포함되어 있을 경우 경로의 크기가 커짐에 따라, 마치 더욱 더 유용한 것처럼 나타나기 때문이다.
실제로 알고리즘이 작용하는 방법은 간단하다. 목표 상태를 나타내는 노드가 생성될 때까지, 매 단계마다 하나의 노드를 확장 전개하는 과정이다. 각 단계마다 지금까지 만들어졌지만 아직 확장 전개되지 않은 노드 중 풀이로 이끌 가능성이 가장 높은 노드를 선택한다. 선택된 노드의 후계 노드를 생성하여, 여기에 경험적 지식에 사용되는 평가 함수를 적용하고, 이들 후계 노드 중 이전에 만들어진 것을 조사하여 OPEN 목록에 첨가한다. 이 과정이 아래에서 상세히 설명된다.
A* 알고리즘
1. 출발 상태의 노드를 포함한 OPEN 에서 시작하라. 이 노드의 g 값에 0 을, h' 값에 임의의 값을, 따라서 f' 에 h' + 0 즉 h' 의 값을 주어라. CLOSED 는 빈 목록으로 한다.
2. 목표 상태를 찾을 때까지 다음 과정을 반복 수행하라 : 만약 OPEN 에 어느 노드도 존재하지 않는다면, 실패이다. 그렇지 않다면 OPEN 에서 가장 작은 f' 값을 가진 노드를 선택하라. 이것을 BESTNODE 라 하자. OPEN 에서 그것을 들어내 CLOSED 에 넣어라. BESTNODE 가 목표 노드인지 조사하라. 그렇다면 해답이 존재한다고 보고하라 (여기서 해답은, 찾는 것이 노드라면 BESTNODE 가 되고, 찾고자 하는 것이 경로라면 출발 상태와 BESTNODE 를 연결한 경로가 된다). 그렇지 않다면, BESTNODE 의 후계 노드를 생성하라. 그러나 아직 BESTNODE 에 이 노드들을 지적하는 포인터를 정하지 말라 (먼저 이들 중에 이미 만들어진 노드가 존재하는지 조사해야 한다). 각 SUCCESSOR 에 대해 다음을 수행하라.
1) SUCCESSOR 에 BESTNODE 를 지적하는 링크를 만들어라. 이 후진 링크는 풀이를 얻었을 때, 풀이로 이끈 경로를 회복하기 위해 사용된다.
2) g(SUCCESSOR) = g(BESTNODE) + BESTNODE 에서 SUCCESSOR 를 얻기 위해 소요된 비용을 계산한다.
3) SUCCESSOR 가 이미 OPEN 목록에 있는 노드 (즉, 이미 만들어졌지만 수행되지 않은 노드) 인지 조사하라. 만약 그렇다면 이것을 OLD 라 하라. 이 노드가 이미 그래프에 존재하기 때문에, SUCCESSOR 를 버리고, BESTNODE 의 후계 노드 목록에 OLD 를 첨가한다. OLD 의 부모 링크가 BESTNODE 를 지적하도록 수정해야 할지를 결정해야 한다. SUCCESSOR 로 오는 경로의 g 값이, OLD 로 오는 현재까지 얻은 최적 경로에 대한 g 값보다 작을 수 있다. 현재까지 얻은 최적 경로를 지나 SUCCESSOR 로 오기 위해 소요된 비용이 더 적은지 결정하기 위해 각각의 g 값을 비교, 조사하라. 만약 OLD 와 관련된 비용이 더 적다면, 다음 단계를 수행하라. 그러나 SUCCESSOR 와 관련된 비용이 더 적다면, 부모 링크가 BESTNODE 를 지적하도록 g(OLD) 에 새로운, 더 적은 비용이 드는 경로를 기록하고, g'(OLD) 를 수정하라.
4) 만약 SUCCESSOR 가 OPEN 에 없다면, CLOSED 에 있는지 조사하라. 만약 그렇다면, 이 노드를 CLOSEDOLD 라 하고, BESTNODE 의 후계 노드 목록에 OLD 를 첨가하라. 새로운 경로나 이미 조사된 경로 중, 단계 2.3 에서처럼 어느 것이 더 효율적인지를 조사하여 부모 링크와, g, f' 의 값을 적절히 정하라. 만약 OLD 로 오는 더 좋은 경로를 발견했다면, OLD 의 후계 노드에 이 사실을 전달하여야 한다. OLD 는 그것의 후계 노드를 지적한다. 각 분지가 OPEN 에 있는 노드로 끝나거나, 혹은 노드를 지적하도록 한다. 새로운 비용을 후계 노드에 전달하기 위해서는 OLD 에서부터 트리의 깊이 우선 탐색을 수행하여 각 노드의 g 값 (결국 f' 값) 을 수정하고, 후계 노드가 없는 노드나 혹은 더 좋은 경로가 이미 발견된 노드에 도달했을 때 분기를 끝마친다. 이 조건은 쉽게 조사할 수 있다. 각 노드의 부모 링크가 최적으로 알려진 그것의 부모를 지적하도록 한다.
5) 만약 SUCCESSOR 가 OPEN 에도 CLOSED 에도 포함되어 있지 않다면, 그것을 OPEN 에 넣고, BESTNODE 의 후계 노드 목록에 첨가하라.
f'(SUCCESSOR) = g(SUCCESSOR) + h'(SUCCESSOR) 를 계산하라.
A* 알고리즘에서 여러 가지 흥미있는 것을 발견할 수 있다. 첫번째는 함수 g 의 역할이다. 노드 자체의 유용성뿐만 아니라, 그 노드를 포함하고 있는 경로의 유용성 (h' 에 의해 추정됨) 을 토대로, 함수 g 를 사용하여 다음 단계에서 전개 확장될 노드를 선택한다. f' 에서 g 의 역할은 항상 목표 상태에 가장 가까운 방향으로 확장 전개되는 노드를 선택하는 것이다. 풀이를 얻기 위한 경로에 관심을 갖는다면, 특히 g 가 유용하게 사용된다. 그러나 경로와는 관계없이 단지 풀이만 얻고자 하는 경우, g 를 항상 0 으로 정의하여 목표에 가장 가까운 노드를 선택한다. 최소의 단계 수를 포함한 경로를 찾기 원한다면, 한 노드에서 그것의 후계 노드로 갈 때 소요되는 비용을 상수 (일반적으로 1) 로 정한다. 적용할 때 드는 비용이 서로 다른 규칙을 포함하고 있는 생성 시스템을 사용하여 가장 적은 비용의 경로를 찾고자 한다면, 한 노드에서 후계 노드로 갈 때 소요되는 비용에 생성 시스템내 작용자, 즉 규칙의 비용을 반영시킨다. A* 알고리즘은 최소 비용의 경로를 찾을 때도, 혹은 풀이를 이끄는 경로를 가능한 한 빨리 찾을 때도 사용될 수 있다.
두번째는 한 노드로부터 목표 노드까지의 거리를 나타내는 h 의 추정값인 함수 h' 이다. h' 가 h 의 완전한 추정값이라면, A* 는 어떤 탐색도 수행하지 않고, 즉시 목표 상태를 찾을 것이다. h' 가 효율적일수록 목표 상태에 가깝게 접근할 것이다. 만약 h' 가 항상 0 이라면 탐색은 g 에 의해 제어되고, 또한 g 도 0 이라면, 탐색은 임의로 수행된다. h' 가 0 일 때 만약 g 가 항상 1 이라면, 탐색은 나비 우선 탐색이다. 만약 h' 가 완전하지도, 0 도 아니라면 어떤 일이 일어날까? 이 경우 탐색 과정에서 발생할 수 있는 것에 대해 알아 보자. 만약 h' 가 h 를 과대 평가하지 않는다면, 최적 경로가 존재할 경우, A* 알고리즘은 목표 상태로 가는 최적 경로 (g 에 의해 결정) 를 반드시 찾는다.
그림 13 에 보여진 상황을 살펴 보자. 모든 링크에 대한 비용을 1 이라 하자. 처음에 A 를 제외한 모든 노드가 OPEN 목록에 있다 (물론 그림은 노드 B 와 E 가 전개 확장된 두 단계 이후의 상태를 나타낸다). 각 노드에 대해 f' 는 h' 와 g 의 합으로 표시되었다. 이 예에서, 노드 b 가 가장 적은 f' 값 4 를 가졌기 때문에, 먼저 전개 확장된다. 노드 E 만이 노드 B 의 후계 노드이고, 목표 상태로부터 3 만큼 떨어져 있다고 가정하자. f'(E) 와 f'(C) 는 5 로 같다. 이런 상황에서는 현재까지 따라온 경로를 택한다고 가정하자. 따라서 E 를 전개 확장한다. 노드 F 만이 노드 E 의 후계 노드이고, 목표로부터 3 만큼 떨어져 있다고 가정하면, 다음 단계에서 사용될 노드를 위해 더 이상 지금까지 따라온 경로를 따라 내려갈 수 없고 후진해야 한다. f'(E) = 6 이고 f'(C) = 5 이다. 따라서 다음에 노드 C 를 전개 확장한다. h(B) 를 원래 값보다 작게 추정했기 때문에 이런 불필요한 노력을 하게 된 것이다. 그러나 결국에 가서 추정했던 것보다 B 가 더 멀리 떨어져 있다는 것을 발견하게 되고, 후진하여 다른 경로를 찾기 시작한다.
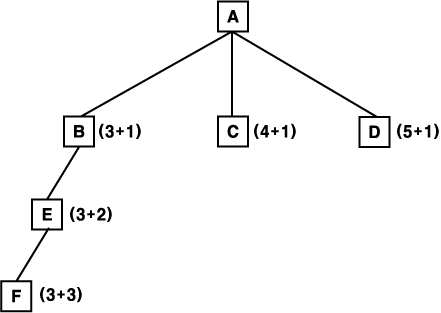
그림 13 h' 가 h 를 과소 평가할 경우
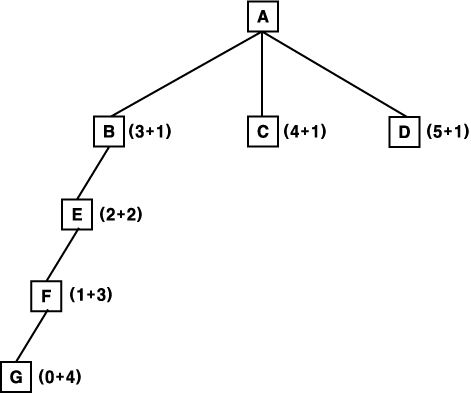
그림 14 h' 가 h 를 과대 평가할 경우
그림 14 에 보여진 상황을 살펴 보자. 첫번째 단계에서 B 를 전개 확장하고, 두번째 단계에서 E 를 전개 확장한다. 다음 단계에서 F 를 확장하여, 마침내 G 를 얻어 길이 4 의 풀이 경로를 얻는다. 그러나 D 로부터 직접 풀이로 가는 길이 2 의 경로가 존재한다고 가정하면, 결코 이 경로를 얻을 수 없다. h(D) 를 원래 값보다 높게 추정했기 때문에, D 가 부적합한 노드로 보였고, 이 D 를 전개 확장하지 못한 채, 다른 좀더 부적합한 풀이를 찾게 될 것이다. 일반적으로 h' 가 h 를 과대 평가할 경우, 모든 경로가 최적 경로보다 길어질 때까지 그래프를 모두 전개 팽창하지 않는다면, 가장 적은 비용의 최적 경로를 찾지 못할 수가 있다. 그러나 일반적으로 반드시 최적해를 찾아야 하는 것은 아니기 때문에, 이것은 그다지 문제시 되지 않는다.
세번째는 트리와 그래프간의 관계이다. A* 알고리즘을 그래프에 적용할 때, 매우 일반적인 형태로 기술했다. 물론, 새로이 생성된 노드가 이미 OPEN 이나 CLOSED 에 존재하는 노드인지 조사하는 단계를 생략하여, 트리에 적용하기 알맞도록 A* 알고리즘을 단순화할 수 있다. 이 경우 더욱 빨리 노드를 만들어낼 수 있지만, 동일 탐색을 여러 번 수행해야 하는 결점이 있다.
(5) 문제 축소 방법 (Problem Reduction)
지금까지 목표로 이끄는 하나의 경로를 찾기 위해 OR 그래프를 탐색하는 방법에 대해 논의했다. 풀고자 하는 문제 중에는, 문제를 여러 개의 작은 부분으로 분해하여 이들 부분적인 문제에 대해 각각 풀이를 얻은 후, 이것들을 하나로 결합하면 원래 풀고자 하는 문제의 풀이를 얻을 수 있는 종류가 있다. 이러한 종류의 문제에는 AND-OR 그래프를 사용하는 것이 더욱 효과적이다. 문제를 분해 (decomposition), 혹은 축소 (reduction) 하면, 임의 개의 후계 노드를 가진 AND 링크가 만들어 지는데, 원래 문제의 풀이를 얻기 위해서는 이들 후계 노드 각각에 대해 모두 풀이를 찾아야만 한다. 또한 OR 그래프에서처럼, 하나의 노드로부터 여러 개의 링크가 나올 수 있는데, 이것은 문제를 풀 수 있는 방법이 여러 개 존재함을 의미한다. 이러한 이유 때문에, 위의 구조를 단순히 AND 그래프라 하지 않고 AND-OR 그래프라 한다. 그림 15 에 AND-OR 그래프 (트리도 가능) 의 한 예가 소개되었다. AND 링크는 모든 구성원을 연결하는 선으로 표시한다.
그림 15 간단한 AND-OR 그래프
풀이를 찾기 위해 AND-OR 그래프를 이용한다면 A* 알고리즘과 비슷하면서, AND 호를 적절히 처리할 수 있는 알고리즘이 필요하다. 이 알고리즘에 의해, 그래프의 출발 노드로부터 목표 상태, 즉 풀이 상태를 나타내는 노드를 연결하는 경로를 찾는다.
또한 AND 링크를 구성하고 있는 각 요소는 그들 자신의 풀이 노드를 찾아야 하기 때문에 한 개 이상의 풀이 상태에 도착한다.
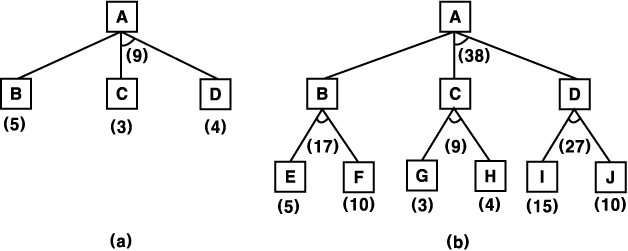
그림 16 AND-OR 그래프
A* 알고리즘이 AND-OR 그래프의 탐색에 부적합한 이유를 설명하기 위해 그림 16 (a) 를 살펴 보자. 루트 노드 A 를 전개 확장하여, 하나는 B 를, 다른 하나는 C 와 D 를 이끄는 두 개의 링크를 얻었다. 각 노드에 표시된 숫자는 그 노드에 대한 f' 의 값이다. 모든 연산 작용의 수행에는 균일한 비용이 소모되며, 하나의 후계 노드를 가진 링크를 처리하기 위해서는 1 의 비용이, 여러 개의 후계 노드를 가진 AND 링크의 경우, 각 성분을 처리하기 위해 1 의 비용이 소모된다고 가정하자. 가장 작은 f' 값을 가진 노드를 다음 단계에서 전개 확장될 노드로 선택할 경우, 노드 C 가 선택되어야 한다. 그러나 현재 이용 가능한 정보에 의하면 노드를 이용하기 위해서는 노드 D 도 또한 이용해야 하기 때문에 이 AND 링크를 처리하기 위해 총비용 9(B + C + 2) 가 필요하지만, 노드 B 를 지나갈 경우, 총비용 6 이 필요함을 알 수 있고 따라서 B 를 지나가는 경로를 조사하는 것이 더욱 효율적임을 알 수 있다. 다음 단계에서 전개 확장될 노드를 선택할 때 그 노드에 대한 f' 값뿐만 아니라, 그 노드가 출발 노드로부터의 최적 경로에 포함되어 있는지의 여부도 고려해야 한다. 그림 16 (b) 에 보여진 트리로부터 이것을 더욱 명백히 알 수 있다. 가장 유망한 노드는 f' 의 값으로 3 을 가진 노드 G 이다. 이것은 총비용 a 를 필요로 하는 가장 유망한 링크 G-H 의 일부분이다. 그러나 노드 G 를 사용하려면, 또한 총비용 27 을 필요로 하는 링크 I-J 도 사용해야 하기 때문에, 현재 최적 경로의 부분이 되지 못한다. 총비용 18 이 필요한 A 로부터 B 를 지나 E 와 F 로 가는 경로가 더 효율적이다. 따라서, 다음에 노드 G 를 전개 확장하는 것이 아니라, E 와 F 를 조사한다. 즉 암시적인 AND-OR 그래프를 탐색하기 위해, 각 단계마다 다음 세 가지 작업을 수행해야 한다.
- 출발 노드에서 시작하여 현재의 최적 경로를 따라 그래프를 탐색하고 그 경로에 존재하면서, 아직 전개 확장되지 않은 노드를 모은다.
- 이 확장되지 않은 노드 중 하나를 선택하여 전개 확장한다. 이것의 후계 노드도 그래프에 첨가하고, 각각에 대해 f' 를 계산한다 (g 는 고려하지 않고 h' 만을 사용한다. 이유는 다음에 설명한다).
- 후계 노드에 의해 제공된 정보를 반영하기 위해 새로이 전개 확장될 노드의 추정 값 f' 를 변화시키고, 그래프를 통해 추진하면서 이 변화를 전달한다. 그래프의 위쪽으로 가는 동안, 방문한 각 노드에 대해 그것의 후계 링크 중 어느 링크가 가장 유망한 것인지를 결정하여, 현재 최적 경로의 부분으로 그것을 표시하라. 이로 인해 현재의 최적 경로가 수정된다. 트리를 후진 방문하면서, 변화된 비용 추정값을 전달하는 것은 확장되지 않은 노드만을 조사하는 A* 알고리즘에서는 불필요한 작업이다. 그러나 현재 최적이 되는 경로를 선택하기 위해서는, 새로 전개 확장된 노드를 다시 조사해야 하기 때문에, f' 값이 이용 가능한 최적 추정값이 되어야 한다.
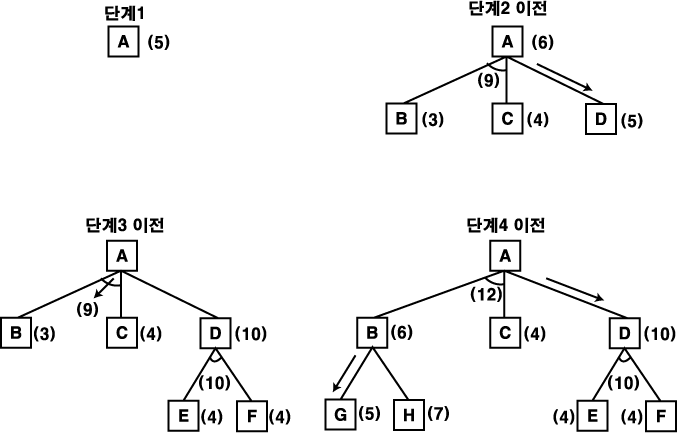
그림 17 AO* 알고리즘의 작동
이 과정이 그림 17 에 보여진다. 단계 1 에서 존재하는 노드는 노드 A 하나로서, 현재 최적이 되는 경로의 끝에 있다. 이것을 확장 전개하여 노드 B, C 와 D 를 얻는다.
노드 B 와 C 에 대한 총비용은 9 이며, 노드 D 에 대한 총비용은 6 이기 때문에, 노드 D 에 대한 링크가 노드 A 로부터 나오는 노드 중 가장 유망한 링크로 표기된다 (표시된 링크는 그림에서 화살표로 나타낸다). 단계 2 에서 전개 확장될 노드로 노드 D 를 선택한다. 이 단계에서 총비용의 추정값이 10 인 노드 E 와 F 에 대한 새로운 AND 링크가 만들어진다. 따라서 노드 D 의 D 값을 10 으로 수정한다. 한 레벨 더 후진하여 AND 링크 B-C 가 노드 D 에 대한 링크보다 더 유용한 것을 알게 되고, 이것을 현재의 최적 경로로 표시한다. 단계 3 에서는, 노드 A 로부터 그 링크를 따라 탐색하면서 확장되지 않은 노드 B 와 C 를 발견한다. 만약 이 경로를 따라 풀이를 찾고자 한다면, 노드 B 와 C 를 전개 확장해야 하는데, 이 중 노드 B 를 먼저 탐색한다. 노드 B 를 전개 확장하여 하나는 노드 G 로 하나는 노드 A 로 가는 두 개의 링크를 얻는다. f' 값을 후진 전달하여, B 의 f' 값을 6 으로 수정한다. 따라서 AND 링크 B-C 의 총비용은 12 (6 + 4 + 2) 로 수정된다. 이로부터 노드 D 에 대한 링크가 노드 A 로부터의 더 좋은 경로가 됨을 알 수 있다. 따라서 현재의 최적 경로로 이것을 표시하고, 단계 4 에서 노드 E 와 노드 F 를 전개 확장한다. 풀이를 찾거나, 모든 경로를 전부 조사하여 풀이가 없음을 알게 될 때까지 이 과정을 수행한다.
A* 알고리즘이 AND-OR 그래프를 탐색하기에 부적합한 두번째 이유는, 노드로부터 노드로의 개개 경로가 AND 링크에 의해 연결되어 만들어져 있다면, 이들을 모두 고려해야 한다는 점이다. A* 알고리즘에서 한 노드로부터 다른 노드로 가는 바람직한 경로는 항상 가장 작은 비용을 가진 경로이다. 그러나 AND-OR 그래프를 탐색할 경우 항상 그런 것은 아니다.
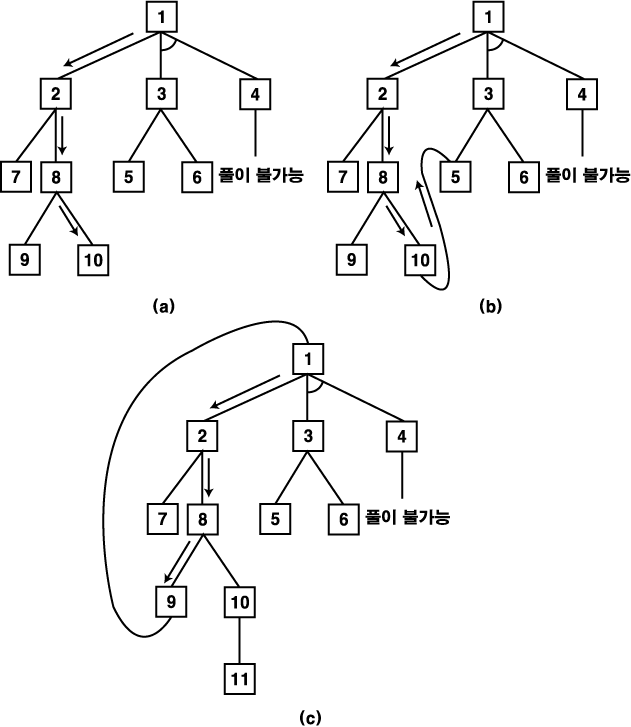
그림 18 긴 경로가 더 나을 경우
그림 18 (a) 에 소개된 예를 살펴 보자. 노드에 표시된 숫자는 노드가 생성된 순서를 나타낸다. 다음 단계에서 노드 10 을 전개 확장하여, 그것의 후계 노드 중의 하나로 노드 5 를 얻었을 때의 상황이 그림 18 (b) 에 모여진다. 노드 5 로 오는 이 새로운 경로는 노드 3 을 지나 노드 5 로 오는 경로보다 길다. 그러나 노드 3 을 지나는 경로를 사용하기 위해서는 노드 4 도 사용해야 하는데, 노드 4 는 풀 수 없다는 정보가 이미 알려져 있기 때문에, 노드 10 을 사용하는 것이 효과적이다.
A* 알고리즘이 AND-OR 그래프를 처리하기에 부적합한 세번째 이유는, AND-OR 를 처리하기 위한 알고리즘은 결코 어떤 사이클도 포함하고 있지 않은 그래프에서 작용한다는 것이다. 이는 어떤 순환 경로도 저장할 필요가 없기 때문에 AND-OR 그래프에 사이클이 없음을 보장할 수 있다. 순환 경로는 수학에서 정리를 증명할 때 발생할 수 있는 순환 추론을 나타낸다. Y 를 증명하며, X 를 증명할 수 있음을 보인 후에, 다시 X 를 증명하면, Y 를 증명할 수 있음을 보일 수 있다. 그러나 이런 순환 경로로는 정리를 증명할 수 없다. 순환 경로는 해답을 찾는데 전혀 영향을 주지 않기 때문에, 그래프에서 제거할 수 있다. 탐색 그래프에서 사이클을 제거함으로써, 탐색 알고리즘 중 간결해지는 부분이 있지만, 이로 인해 더욱 복잡해지는 부분도 있다. 후계 노드를 만들고, 이것이 이미 그래프에 존재하는 노드임을 알게 되면, 이미 전개 확장된 노드 중에서 이 노드를 조상으로 하는 노드가 있는지 조사해야 한다. 만약 그렇지 않다면 (사이클이 만들어지지 않는다), 이 노드로 오는 새로이 발견된 경로를 그래프에 포함시킨다. 이런 조사를 함으로써 그림 18 (c) 와 같은 그래프가 만들어지는 것을 예방할 수 있다.
이제, AND-OR 그래프의 독학적 탐색을 수행하는 알고리즘을 정확히 알아 보자. 이 알고리즘을 AO* 알고리즘이라 한다.
A* 알고리즘에서 사용했던 OPEN 과 CLOSED 목록 대신, 탐색 그래프 중 지금까지 명백히 만들어진 부분을 나타내기 위해 하나의 구조 G 를 사용한다. 그래프의 각 노드는 직속 후계 녿그나 직속 전임 노드를 가르키는 링크를 가지고 있으며, 또한 이 노드로부터 풀이 노드까지 경로의 비용 추정값인 h' 값을 가지고 있다. 출발 노드로부터 현재 노드까지의 비용인 g 값은 저장하지 않는다. 하나의 동일한 상태를 만드는 경로가 여러 개 존재할 수 있기 때문에, 단 하나의 g 값을 계산하기란 불가능하다. 이미 알려진 최적 경로의 하향식 트래버셜이기 때문에, g 값은 불필요하며, 이는 최적 경로에 있는 노드만이 확장을 위해 고려됨을 보장한다. h' 는 노드의 유용성에 대한 추정값이다.
탐색을 위해 상한값을 사용하는데, 만약 풀이의 추정 비용이 상한값보다 크게 되면 탐색을 중단한다. 상한값은 그 값보다 높은 비용을 필요로 하는 풀이는 모두 비현실적이기 때문에 (비록 풀이를 찾는다 할지라도) 이를 처리하기 위해 사용된다.
AO* 알고리즘
1. G 에 초기 상태를 나타내는 노드를 넣어라 (이 노드를 INIT 라 한다).
h' (INIT) 를 계산하라.
2. INIT 에 SOLVED 라는 명칭이 붙을 때까지, 혹은 INIT 의 h' 값이 상한값보다 크게 될 때까지 다음 과정을 반복 수행하라 :
1) INIT 로부터 표시된 링크를 찾아 전개 확장을 위해, 그 경로에 나타난, 아직 전개 확장되지 않은 노드 중 하나를 선택하라. 선택된 노드를 NODE 라 부른다.
2) NODE 의 후계 노드를 만들라. 만약 후계 노드가 없다면, 상한값에 NODE 의 h' 값을 주어라. 이것은 NODE 가 풀 수 없는 노드임을 나타낸다. 만약 후계 노드가 있다면, SUCCESSOR 라 불리는 각 노드에 대해 다음 작업을 수행하라 :
① 그래프 G 에 SUCCESSOR 를 넣어라.
② SUCCESSOR 가 단말 노드이면, SOLVED 라 명하고,
③ SUCCESSOR 가 단말 노드가 아니면, h' 값을 계산하라.
3) 다음을 수행하여, 새로이 얻은 정보를 그래프 위쪽으로 전달하라 : SOLVED 라 표시되었거나, h' 값이 변하여 이 값을 전임 노드들에 전달할 필요가 있는 노드의 집합을 S 라 하자. S 의 초기값으로 NODE 를 주어라. S 가 공집합이 될 때까지 다음 작업을 반복 수행하라 :
① S 에 포함되어 있는 노드 중에서, 그것의 후손 노드가 전혀 G 에 포함되어 있지 않는 노드를 택하라 (즉, 수행할 노드 각각에 대해 이것의 전임 노드를 수행하기 전에, 이 노드 자체부터 수행한다). 이 노드를 CURRENT 라 부르고, S 에서 제거하라.
② CURRENT 로부터 나오는 링크 각각에 대해 비용을 계산하라. 각 링크의 비용은 링크의 끝에 있는 각 노드들의 h' 값을 더한 뒤 이것을 다시 링크 자체의 비용과 합한 것이다. CURRENT 로부터 나오는 링크에 대해 계산된 비용의 최소값을 CURRENT 의 새로운 h'값으로 한다.
③ 전단계에서 계산된 최소 비용을 가진 링크를 표시함으로써, CURRENT 로부터의 최적 경로를 표시하라.
④ 새로이 표시된 링크를 따라, CURRENT 에 연결된 모든 노드들이 SOLVED 로 명해졌으면, CURRENT 를 SOLVED 로 표시하라.
⑤ CURRENT 가 SOLVED 라 표시되었거나, CURRENT 의 최소 비용이 바뀌었다면 그것의 새로운 상태를 그래프 위로 전달해야 한다. 따라서 CURRENT 의 모든 전임 노드들을 S 에 첨가하라.
이 알고리즘의 작용 과정에서, 여러 가지 사항을 관찰할 수 있다. 단계 2.3.5 에서, 비용이 바뀐 노드의 전임 노드는 비용의 수정을 요하는 노드의 집합에 첨가된다. 위 알고리즘에 기술된 것처럼, 비용이 바뀐 노드의 모든 전임 노드를 그 집합에 집어 넣는다. 이로 인해, 이미 적합하지 않다고 알려진 많은 경로를 따라 후진하면서, 비용의 변화를 전달할 수 있다. 예를 들어, 그림 19 에서 보여지듯이, C 를 지나가는 경로가 B 를 통해 지나가는 경로보다 항상 유용하기 때문에, B 를 지나가는 경로를 전개 확장하는 것은 낭비이다. 그러나 노드 E 의 비용이 수정될 때, 이 변화가 노드 C 뿐만 아니라 노드 B 에도 전달되지 않는다면, 노드 B 가 더 유용한 것처럼 보일 수 있다.
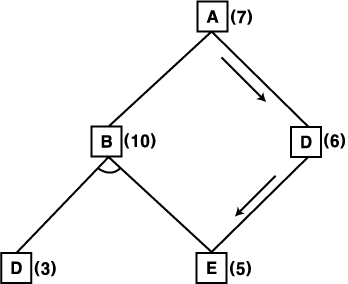
그림 19 불필요한 후진 전달
예를 들어 노드 E 를 전개 확장하여, 이것의 비용이 10 으로 수정되었다고 하자. 이때 노드 C 의 비용은 따로 수정된다. 이것만 수행할 경우, 노드 B 를 통해 가면 11 의 비용이 들고, 노드 C 를 통해 지나가면 12 의 비용이 소요되는 것으로 나타나기 때문에, 노드 A 로부터 출발하여 노드 B 를 통해 지나가는 경로를 가장 유망한 경로로 선택한다. 이 예에서는 노드 D 를 전개 확장하는 다음 단계에서 이 실수를 알게 된다. 노드 D 에 대한 비용의 변화를 노드 B 로 전달하여, 노드 B 의 비용을 다시 계산할 때, 변화된 노드 E 의 비용이 사용될 것이다. 새로 계산된 노드 B 의 비용이 다시 노드 A 로 전달되고, 이로부터 노드 C 를 통해 지나가는 경로가 더 적합한 것임을 알게 된다. 따라서 B 를 전개 확장하기 위해 시간이 소모되었을 뿐, 풀이를 얻는데는 영향을 받지 않는다. 그러나 비용이 변한 노드가 탐색 그래프의 더욱 밑에 위치한다면, 착오를 결코 발견하지 못할 수도 있다. 그림 20 (a) 에 이것의 예가 보여진다. 그림 20 (b) 처럼 노드 G 의 비용이 변할 때, 이 변화를 즉시 노드 E 로 전달하지 않는다면, 변화가 이후에 결코 반영되지 않기 때문에, 노드 B 를 통해 지나가는, 최적이 아닌 풀이 경로를 얻게 된다.
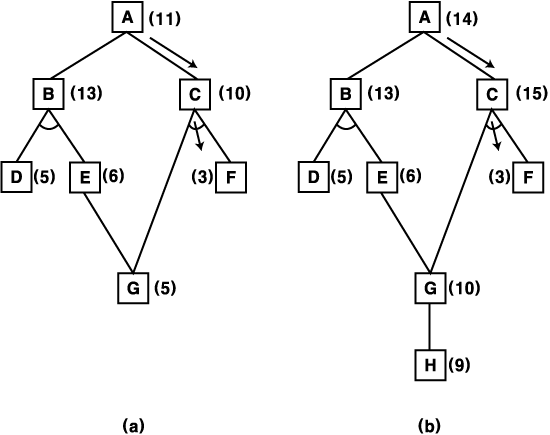
그림 20 반드시 필요한 후진 전달
그림 21 부속 목표들 간의 상호 작용
AO* 알고리즘에서 관찰되는 두번째 사항은 AO* 알고리즘이 부분 목표들 간의 상호 작용을 고려하지 못한다는 점이다. 이를 설명하기 위해 그림 21 을 살펴 보자. 노드 C 와 노드 E 가 결국에 가서는 풀이를 이끈다고 가정할 때, AO* 알고리즘을 사용하여 이 두 노드를 모두 포함한 완전한 풀이를 얻을 수 있다. AND-OR 그래프 상에 있는 노드 A 를 풀기 위해서는 반드시 노드 C 와 D 에 대한 풀이를 찾아야 한다. 그러나, 알고리즘은 노드 C 의 풀이 과정과 노드 D 의 풀이 과정을 완전히 별개의 것으로 간주하여, 노드 D 를 풀기 위해 다음에 전개 확장될 노드를 노드 E 를 선택한다. 그러나 노드 C 또한 노드 A 를 풀기 위해 반드시 풀어져야 하기 때문에, 노드 D 를 만족시키기 위한 것으로 이것을 사용하는 것이 더욱 효과적이다. 그러나 AO* 알고리즘은 이러한 상호 작용을 고려하지 못하기 때문에, 최적이 아닌 경로를 찾게 될 것이다. 8-1 절에서 이 문제를 다루었다.
(6) 제한 조건의 만족 방법 (Constraint Satisfaction)
인공 지능의 많은 문제들은 주어진 조건을 만족시켜야 하는 문제로 볼 수 있는데, 이러한 문제의 목표 상태는 주어진 제한 조건을 만족시킨 문제 상태이다. 2-4 절에서 논의된 암호 산술 문제와 10 장에서 논의될 인식 문제가 여기에 포함된다. 디자인 작업을 수행할 때, 제한된 시간, 비용 그리고 재료를 만족시키는 범위 내에서 일을 해야 하기 때문에, 디자인 작업도 제한 조건의 만족 문제로 볼 수 있다. 제한 조건의 만족 문제를 풀기 위해 특별히 새로운 탐색 방법이 필요한 것은 아니고, 지금까지 논의한 탐색 방법들을 이용해 풀 수 있다. 주어진 제한 조건을 만족시켜야 하는 문제의 구조적 특성 때문에, 문제를 풀어감에 따라 변하는 제한 조건의 목록과 더불어 문제 상태에 대한 기술을 논의하고, 또한 이 목록을 처리하는 탐색 기법을 논의하는 것이 효율적이다. 즉, 문제의 풀이를 찾는 탐색을 수행할 때, 동시에 두 개의 탐색이 필요하다.
하나는 제한 조건 목록의 문제 공간에서 수행되는 탐색이고, 다른 하나는 원래 문제 공간에서 수행되는 탐색인데, 이때 규칙의 패턴과 경험적 지식에 사용되는 평가 함수가 제한 조건 공간 내의 위치를 알려준다.
제한 조건의 만족 방법을 보는 또 다른 견해는 단일 유형의 언덕 오르기 방법 (즉, 전체적인 최대값만 존재하고, 다른 어떤국부적인 최대값은 존재하지 않는다) 으로 보는 것이다. 언덕 오르기 방법이 수행되는 문제 공간내의 각 상태는 아직 제외되지 않은 가능한 풀이의 갯수를 나타낸다. 이 방법이 수행되는 과정은 가능한 풀이의 갯수가 줄어드는 상태를 향해 움직이는 것으로 정의한다.
제한 조건의 만족 방법의 과정에 대한 일반적인 형태는 다음과 같다 :
1. 완전한 풀이가 발견되거나, 혹은 모든 경로를 조사해 풀이가 없다는 것을 알게 될 때까지 다음을 수행하라 :
1) 탐색 그래프에서 전개 확장되지 않은 노드를 선택하라.
2) 새로운 가능한 제한 조건을 모두 만들기 위해, 선택된 노드에 제한 조건에 대한 유추 규칙을 적용하라.
3) 제한 조건의 집합이 모순을 포함한다면, 이 경로를 무용한 것으로 표시하라.
4) 제한 조건의 집합이 완전한 풀이를 나타낸다면 성공으로 표시하라.
5) 모순도 완전한 풀이도 발견되지 않았다면 제한 조건의 현재 집합과 모순됨이 없이 일관되는 새로운 부분적 풀이를 만들기 위해, 문제 공간의 규칙을 적용하라. 이 부분적 풀이를 탐색 그래프에 넣어라.
위 과정에서 많은 중요한 점을 발견할 수 있다. 단계 1.1 에서는 단순히 전개 확장되지 않은 노드를 선택한다고 기술했지만, 노드를 선택하는 방법에 따라, 알고리즘의 행동이 크게 영향을 받는다. 또한 제한 조건의 목록과 문제 상태를 표기하는 방법에 대해서도 기술하지 않았다. 여러 다양한 방법을 사용하여, 이 문제를 처리할 수 있다.
다음의 예를 통해, 알고리즘이 작용하는 방법과 이 문제를 해결하는 방법을 쉽게 이해할 수 있다.
|
문제 |
SEND + MORE MONEY |
|
|
제한 조건 |
|
|
|
어떠한 문자도 같은 값을 갖지 않는다. 산술 연산 규칙을 따라야만 한다. | ||
|
초기 문제 상태 |
S = ? E = ? N = ? D = ? M = ? O = ? R = ? Y = ? |
C1 = ? C2 = ? C3 = ? C4 = ? |
그림 22 암호 산술 문제
그림 22 에 소개된 암호 산술 문제를 살펴 보자. 제한 조건의 초기 목록과 초기 문제 상태가 또한 그림에 보여진다. 목표 상태는 모든 제한 조건을 만족하는 방법으로 모든 문자에 숫자를 정해 주는 문제 상태이다.
풀이 과정은 사이클로 수행된다. 즉 사이클마다 다음 두 가지가 행해진다 :
1. 적절한 새로운 제한 조건을 만들기 위해, 제한 조건에 대한 유추 규칙을 적용한다.
2. 제한 조건의 현재 상태에 의해 요구되는 모든 계산을 수행하기 위해, 문자 계산 규칙을 적용하라. 부가되는 계산을 수행하기 위해 다른 규칙을 선택하고, 다음 사이클에서 다시 새로운 제한 조건을 만들어라.
물론, 각 단계마다 여러 개의 규칙이 적용될 수 있기 때문에, 경험적 지식에 사용되는 적절한 평가 함수를 사용하여 먼저 적용할 최적 규칙을 선택한다. 예를 들어, 두 개의 값을 가질 수 있는 문자와, 여러 개의 값을 가질 수 있는 문자가 있다면, 후자보다 전자를 선택하는 것이 더욱 효과적이다. 문제와 제한 조건이라는 두 공간에 많은 중간 단계의 위치를 기록하지 않기 위해, 깊이 우선 탐색 방법을 이용하여 이것을 구현한다. 상호 베타적이 아닌 규칙은 모두 함께 적용할 수 있고, 따라서 하나의 단계로 볼 수 있는데, 이는 암호 산술 문제에서 흔히 볼 수 있다.
그림 23 암호 산술 문제를 푸는 과정
위의 예를 처리하는 처음 몇 단계의 결과가 그림 23 에 나타나 있다. 낮은 레벨에서는, 제한 조건이 결코 없어지지 않기 때문에, 첨가될 조건들만 각 레벨에서 보여진다. 이것은 이 작업 분야와 관련된 골조 문제의 합리적인 풀이이다. 문제를 푸는 과정에서 하나의 긴 목록보다 목록의 집합으로 제한 조건을 사용하는 것이 편리한데, 이것은 기억 공간이라는 면과 후진의 용이면에서 볼 때 효과적이다. 이 문제를 처리하기 위해 하나의 중앙 데이터 베이스에 모든 제한 조건을 기억시키고, 후진 때 전혀 행해지지 않은 것처럼 해야 할 변화를 각 노드마다 기록시킨다. 각 행의 덧셈으로부터 발생한 자리 올림수를 나타내기 위해 C1, C2, C3, C4 를 오른쪽으로부터 사용한다.
처음에, 제한 조건을 만드는 과정은 다음과 같이 수행된다 :
- M = 1 두 개의 한 자리 숫자와 자리 올림수를 더한 것이 19 보다 클 수는 없기 때문이다.
- S = 8 혹은 9, S + M + C3 > 9 (자리 올림수를 만들기 위해), M = 1 을 대입하면, S + 1 + C3 > 9, 즉 S + C3 > 8, 그런데 C3 는 기껏해야 1 이기 때문이다.
- O = 0. 자리 올림수를 만들기 위해, S + M (1) + C3 (≤1) 은 10 이상이 되어야 하는데, 또한 이 값이 11 이상될 수는 없기 때문이다.
실제 문제를 푸는 과정을 시작하자. 제한 조건으로부터 즉시 M 과 O 의 값을 얻을 수 있다. E 의 값으로 2 를 지정하여 다음 사이클을 수행하자.
- N = 3, N = E + O + C2 = 2 + 0 + 1 = 3 이다. 만약 C2 가 0 이라면 N 과 E 가 같아지기 때문에, C2 가 1 이어야 한다.
- R = 8 혹은 9, R + N(3) + C1 (1 혹은 0) = 2 혹은 12, 2 는 불가능하며, R + 3 + (0 혹은 1) = 12 여야 하기 때문에 R = 8 혹은 9 가 된다.
- 가장 오른쪽 행으로부터 2 + D = Y 혹은 2 + D = 10 + Y 을 얻는다.
그러나 이 단계에서 제한 조건을 만드는 과정으로부터 문제를 푸는 과정으로 제어가 넘어가면, 문제 풀이 과정은 제한 조건에 불확실한 것이 포함되어 있음을 알게 된다.
그러나 경우에 따라서는 제한 조건을 만드는 과정으로부터 문제를 푸는 과정으로 제어를 양도하는 것이 더욱 효과적일 때도 있다. 이것은 제한 조건을 만드는 과정에서 제어를 양도하는 것이 더욱 효과적일 때도 있다. 이것은 제한 조건을 만드는 과정에서 이용될 수 있는 선택의 수가 적고, 문제를 푸는 과정에서 이용될 수 있는 선택의 수가 많을 경우 성립한다. 또한 이것을 제한 조건의 만족 문제를 푸는 처음 몇 단계에서는 일반적으로 성립한다. 이러한 특징을 이용해 제한 조건을 만드는 과정은 2 + D = 10 + Y 를 먼저 선택하여 다음과 같은 제한 조건을 만든다 :
- D > 7. 자리 올림수를 만들기 위해 2 + D 가 10 이상이어야 하기 때문에, D 는 8 이상이어야 한다.
이제 문제를 푸는 과정으로 제어가 넘어 간다. 문제를 푸는 과정은 N = 3 임을 기록하고 반드시 8 이나 9 의 값을 가지도록 제한을 받은 변수 D 를 선택한다.
다음 사이클에서, 문제를 푸는 과정은 D = 8 을 사용할 경우 모순이 발생함을 알게 되고, 후진하여 D = 9 를 적용하는데, 이 또한 모순을 유도함을 알게 된다. 이로 인해 제한 조건을 만드는 과정은 제어를 양도받아, 마지막 선택했던 점까지 전체 과정을 후진한다. 여기서 2 + D = Y 이고 C1 = 0 임을 알고, 수행을 진행하지만 2 + D = Y 는 부적합한 것이기 때문에 사용되지 않는다.
이 과정에서 몇 가지 중요한 것을 알 수 있다. 제한 조건을 만드는 규칙에 필요한 것은, 이것이 거짓된 제한 조건을 유추해서는 안된다는 것이다. 또한 이것이 모두 참인 제한 조건을 유추할 필요도 없다. 예를 들면 D > 7 이라는 것을 알았을 때 Y 가 1, 2, 혹은 3 의 값을 가질 수 없다고 주어졌다면, D > 10 이라는 결론을 얻을지도 모른다. 물론 D 가 한 자리 숫자를 표시하기 때문에 이는 불가능하다.
두번째는 관찰할 수 있는 것은 분기 계수를 고려하여 추측 과정의 효율성을 향상시킬 수 있다는 점이다. 이용 가능한 값이 제한을 받지 않는 것보다, 제한을 받는 것을 추측하는 것이 효과적이다. 또한 제한 조건이 OR 의 형태를 가져, 문제를 푸는 과정으로 하여금 수많은 경로 중에서 하나를 선택하도록 하는 것보다, 두 가지 형태만을 가지도록 하는 것이 효과적이다. 선택할 것이 적을 수록, 선택할 것이 많은 것보다 풀이를 얻을 확률이 크다.
세번째는 매 사이클에서 확장 전개될 노드를 선택하는 방법이다. 구현하기 쉽고, 기억 장소면에서 볼 때 효과적이기 때문에, 이 예에서 깊이 우선 제어 방법이 사용되었다. 그러나 다른 제어 방법이 또한 사용될 수 있다.
암호 산술 연산과 같은 제한 조건의 만족 문제를 풀기 위해, 위에서 설명된 방법은 더욱 어려운 문제를 풀기 위해 지금까지 논의된 순수한 탐색 방법의 조합을 보여준다.
(7) 방법-목적 분석 방법 (Means-Ends Analysis)
지금까지 전진 혹은 후진 추론의 탐색 방법에 대해 논의했다. 이는 주어진 문제에 대해 한쪽으로 방향을 선택하여 풀이를 찾아가는 것이었다. 그러나 흔히 양쪽 방향을 혼용하여 사용하는 것이 효과적일 수 있다. 이러한 혼용 방법을 사용하여, 먼저 문제의 중요 부분을 풀고, 다시 여러 개의 중요 부분에 대한 풀이를 함께 결합할 때 일어나는 작은 문제를 풀 수 있는데, 이를 위해 방법-목적 분석 방법이라 불리우는 기법이 사용된다.
방법-목적 분석 방법 (means-ends analysis) 은 현재 상태와 목표 상태간의 차이를 탐지하는데 중점을 둔다. 이러한 차이를 찾으면, 이 차이를 줄일 수 있는 연산자 (operator) 를 찾아야만 한다. 그러나 대부분의 경우, 연산자를 현재 상태에 적용할 수 없기 때문에, 연산자를 적용시킬 수 있는 상태로 만드는 부속 문제 (subproblem) 를 설정한다. 이렇게 해도 원하는 상태를 연산자가 정확히 만들어내지 못할 경우, 유사한 부속 문제를 만들어, 이 문제에 의해 만들어진 상태로부터 목표 상태를 찾도록 한다. 그러나 차이가 올바로 선택되고 연산자가 실제로 이 차이를 효과적으로 줄일 수 있다면, 원래 문제를 푸는 것보다 두 개의 부속 문제를 푸는 것이 훨씬 더 쉽다. 이 두 문제에 방법-목적 분석 방법을 순환적으로 적용할 수 있다. 먼저 큰 문제를 해결하기 위해 차이에 우선 순위 정도를 정하여 높은 우선 순위를 가진 차이가 낮은 우선 순위를 가진 차이보다 먼저 고려되도록 한다.
방법-목적 분석 방법을 이용한 첫번째 인공 지능 프로그램은 범용 문제 풀이 과정 (General Problem Solver) 이다. 이는 인간이 하는 일을 시뮬레이션하는 프로그램을 작성하는 것과 단순히 어떤 방법으로든 문제를 푸는 프로그램을 작성하는 것 사이의 경계를 불투명하게 하는 좋은 예이다.
지금까지 논의했던 문제 풀이 기법에서처럼, 방법-목적 분석 방법은 하나의 문제 상태를 다른 상태로 변화시키는 규칙의 집합에 의해 결정된다. 그러나 이 규칙들 이 양면에 완전한 상태를 기술할 필요는 없다. 그 대신 규칙을 이용하기 위해 만족되어야할 조건 (규칙의 선결 조건이라 불리운다) 을 기술하는 좌측면과 규칙을 적용함으로써 변하는 문제 상태의 면들을 우측면으로 표기한다.
|
연산자 |
|
|
PUSH (obj, loc) |
선결 조건 결과 |
|
CARRY (obj, loc) |
선결 조건 결과 |
|
WALK (loc) |
선결 조건 결과 |
|
PICKUP (obj) |
선결 조건 결과 |
|
PUTDOWN (obj) |
선결 조건 결과 |
|
PLACE (obj1, obj2) |
선결 조건 결과 |
그림 24 로보트의 연산자들
|
|
Push |
Carry |
Walk |
Pick up |
Put down |
Place |
|
물체 이동 |
√ |
√ |
|
|
|
|
|
로보트 이동 |
|
|
√ |
|
|
|
|
물체 제거 |
|
|
|
√ |
|
|
|
물체 올려놓기 |
|
|
|
|
|
√ |
|
아암 비우기 |
|
|
|
|
√ |
√ |
|
물체 집기 |
|
|
|
√ |
|
|
그림 25 차이표
단순한 집안 일을 하는 로보트에 대항 살펴보자. 그림 24 에 선결 조건과 결과로 표현된 이용 가능한 연산자가 보여진다. 그림 25 는 각 연산자가 적합할 때를 나타내는 차이표이다. 이 표에서 보여주듯이, 하나의 차이를 줄일 수 있는 연산자가 여러 개 존재할 수도 있고, 또한 하나의 연산자가 여러 개의 차이를 줄일 수도 있다.
|
A |
B |
C |
D | ||||
|
|
|
|
|
|
|
|
|
|
Push | |||||||
|
출발 상태 |
|
|
|
|
목표 상태 | ||
그림 26 방법-목적 분석 방법의 진전 (CARRY)
로보트가 두 개의 물건이 놓여 있는 책상을 한 방에서 다른 방으로 옮기는 문제가 주어졌다고 가정하자. 물론 책상 위의 물건도 옮겨져야 한다. 출발 상태와 목표 상태 간의 차이는 책상의 위치이다. 이 차이를 줄이기 위해 PUSH 나 CARRY 를 선택할 수 있다. 만약 CARRY 를 먼저 선택한다면 이것의 선결 조건이 만족되어야 한다. 이는 두 개의 차이를 줄여야만 하는 결과를 낳는다. 두 개의 차이는 로보트의 위치와 책상의 크기이다. WALK 를 적용하여 로보트의 위치를 처리할 수 있지만, 물체의 크기를 바꿀 연산자가 없다. 따라서 이 경로를 이용해서는 문제를 풀 수 없다. 다음에 선택될 수 있는 연산자는 PUSH 이다. 그림 26 은 PUSH 를 사용하는 경우에 문제 풀이 과정에 의해 이루어진 진전을 보여준다. 이렇게 하여 유용한 어떤 일을 하는 방법을 찾았지만 아직 이 일을 수행할 수는 없다. 또한 이 일이 수행됐다하여 곧 목표 상태에 이르는 것은 아니다. 따라서 그림 26 에서 보여준 A, B, C, D 의 위치 중 A 와 B 그리고 C 와 D 사이의 차이를 줄여야만 한다.
PUSH 는 세 개의 선결 조건을 가지고 있는데, 이 중 두 개는 출발 상태와 목표 상태간의 차이를 만든다. 책상이 크기 때문에 하나의 선결 조건은 아무런 차이도 만들어내지 못한다. 로보트는 WALK 를 사용하여 올바른 위치로 갈 수 있다. 그러나 PICKUP 을 한번 수행한 후, 두번째 PICKUP 을 수행하여 물건을 치울 수 있다. 그러나 PICKUP 을 한번 수행한 후, 두번째 PICKUP 을 수행하려면 로보트의 팔이 비어야만 하는 또 다른 차이가 발생한다. 이 차이는 PUTDOWN 을 사용하여 줄일 수 있다.
|
A |
|
|
|
|
B |
C |
E |
D | |||||
|
|
|
|
|
|
|
|
|
|
| ||||
|
|
Pick up |
Put down |
Pick up |
Put down |
Push |
|
Place |
| |||||
|
출발 상태 |
|
|
|
|
|
목표 상태 |
| ||||||
그림 27 방법-목적 방법에 의한 진전 (PUSH)
일단 PUSH 가 수행되면 문제 상태가 목표 상태에 가까워지지만 완전한 목표 상태는 아니다. 책상을 옮긴 후 책상 위에 있었던 물건을 다시 올려 놓아야만 한다. PLACE 를 사용하여 물건을 올려놓을 수 있지만 이를 즉시 적용할 수는 없다. 로보트가 물건을 잡아야 하기 때문에 또 다른 차이를 줄여야 한다. 이러한 점에서 문제 풀이 과정에 의해 만들어진 진전이 그림 27 에 보여진다. C 와 E 의 마지막 차이는 로보트가 물건을 다시 집기 위해 WALK 를 사용한 후 PICKUP 과 CARRY 를 순서대로 사용하여 줄일 수 있다.
여기서 보여준 로보트 문제에서는 세부적인 사항이 생략되었다. 그렇지만 차이를 고려하는 순서는 매우 중요하다. 문제에서 차지하는 비중이 큰 차이를 비중이 작은 차이보다 먼저 줄이는 것은 중요한 일이다.
지금까지 논의한 간단한 과정은 복잡한 문제를 풀기에는 부적당하다. 그 이유는 다음과 같다. 차이가 여러 가지 있을 때 이들의 순서는 매우 많다 (n 개의 차이에 대해서는 n! 만큼의 순서가 있다). 또한 하나의 차이를 줄이는 일이 다른 차이를 줄이는 일과 대립될 수 있다. 복잡한 현실 문제의 경우, 필요한 차이표가 매우 크다. 제 8 장에서는 기초적인 방법-목적 분석 방법을 확장하여 이러한 문제점을 해결할 수 있는 방법에 대해 다룬다.
7. 탐색 알고리즘의 분석
지금까지 탐색을 필요로 하는 여러 가지 문제 풀이 방법에 관해 다루었다. 탐색 과정이 사용되는 경우의 중요한 문제점은 이 탐색 과정이 얼마나 좋은 것인가이다. 탐색 과정이 좋다는 뜻은 탐색 과정의 효율과 탐색 과정이 발견한 답의 정확성이 높음을 말한다. 전통적으로, 문제 풀이 알고리즘의 연구에 대한 인공 지능 분야의 방식은 알고리즘을 작성하여 컴퓨터에 의해 수행시켜 몇 개의 예제에 대해 결과를 관찰하는 것이 고작이었다. 이러한 방식은 수학적으로 알고리즘을 분석하거나 이러한 분석이 불가능한 경우 신중하게 선택된 문제들에 대하여 알고리즘의 성능을 통계적으로 분석하는 뛰어난 방식과는 대조를 이룬다. 인공 지능 분야의 방식을 사용하는 데에는 적어도 두 가지 이유가 있으며 이는, 다음과 같다.
- 프로그램이 지적인 일을 수행할 수 있다는 것을 증명하는 것보다 프로그램이 지적인 일을 수행할 수 있다는 사실 자체가 더 흥미 있다.
- 인공 지능 분야의 문제 영역은 일반적으로 매우 복잡하여 프로그램이 주어진 일을 수행할 것이라고 확신시키는 분석적인 증명이 통상적으로 가능하지는 않다. 경우에 따라서 확신시키는 수행 결과에 통계적인 분석을 허용할 만큼 문제의 범위를 잘 나타내는 것조차 가능하지 못할 수도 있다.
두번째 이유는 매우 중요하다. 대부분의 인공 지능 분야 프로그램에 의해 사용되는 지식의 복잡한 구조는 이를 사용하는 프로그램의 수학적 분석을 매우 어렵게 만든다.
그러나 이러한 분야에도 몇 가지 흥미로운 결과가 있다. 또한, 프로그램을 작성할 때 프로그램의 성능에 대하여 정확하게 말할 수 없을지라도 프로그램의 성능을 항상 염두에 두는 일은 중요하다.
비록 고무적인 사항은 아니지만, 이미 앞에서 보인 바와 같이, 탐색 과정의 가장 중요한 분석 결과는 분기 계수가 F 이고, 깊이가 D 인 탐색 트리의 노드 갯수가 FD 라는 사실이다. 이러한 간단한 분석은 다음 두 가지를 말하여 준다.
- 트리 전체를 탐색하는 과정에 대한 개선책을 찾아야 한다. 왜냐하면 수행 시간이 문제 크기에 지수적으로 비례하는 과정은 관심을 갖고 있는 모든 문제를 풀기에 적당치 않다.
- 트리 전체를 탐색하는 과정에 대한 개선책에 의해 걸리는 탐색 시간의 상한값 즉 가장 오래 걸리는 시간을 알 수 있다.
FD 라는 간단한 결과로부터 위의 두 가지 사실을 알 수 있음은 다행이다. 그러면, 이 다음 문제를 생각해 보자. 앞의 제 2 장에서 제시한 대로, 트리 전체를 완전하게 탐색하는 것보다 더 좋은 방법이 몇 가지 있다. 이 방법들은 다음과 같이 세 가지로 분류되고, 각 분류된 방법마다 주요 문제점이 있다.
- 일반적인 방법으로 트리 전체를 완전하게 탐색하여 답을 찾아내는 것과 같은 정도로 만족할 만한 답을 얻을 수 있고 수행 시간은 완전 탐색보다 적게 걸린다. 이 경우의 문제점은 얼마나 빨리 그러한 방법을 찾을 수 있는가이다.
- 몇 개의 문제에 대하여서는 트리 전체를 완전하게 탐색하는 방법과 마찬가지 시간이 소요되나 대부분의 문제에 대하여서는 완전한 탐색보다 시간이 훨씬 더 적게 걸리는 방법으로 일반적인 방법까지도 포함할 수 있다. 이 경우의 문제점은 이 방법이 얼마나 빨리 평균적인 문제를 풀 수 있는가이다.
- 트리 전체를 완전히 탐색하여 얻을 수 있는 답보다 부정확한 답을 주어진 시간 내에 찾아내는 방법이 있다. 이 경우의 문제점은 정답과 이 방법에 의해 얻어진 답과의 오차가 얼마나 되는가이다.
그러나 불행하게도 많은 문제에 대하여 트리 전체를 완전하게 탐색하는 방법과 일반적인 방법을 사용하는 경우에는 수행 시간을 크게 줄이지는 못한다. 예를 들어, 앞의 2-1-2 절에 설명된 분기와 한계에 의한 방법은 완전한 탐색 방법보다 빠를 수 있지만, 수행 시간은 문제 크기에 지수 함수적으로 비례한다. 세일즈 맨의 방문 문제에 대해서는 지수 함수적 알고리즘보다 더 빨리 수행할 수 있는 알고리즘이 알려져 있지 않으며, 또한 아무도 그러한 알고리즘이 알려지리라고 기대하지 않는다. 세일즈 맨의 방문 문제는 NP-완전 문제에 속한다. NP-완전 문제는 평행하게 실행될 수 있는 모든 일들이 동시에 처리되는 비 결정적 (nondeterminstic) 컴퓨터에 의해 수행될 때 다항 함수적 시간이 걸리는 알고리즘에 의해서만 풀릴 수 있는 문제이고, 이러한 문제를 일반적인 컴퓨터에 의해 풀 때에는 지수 함수적 시간이 걸리는 알고리즘만 존재한다. 이러한 부류의 문제들에 대해서는, 이 부류에 속하는 어떤 문제가 일반적인 결정적 (determinstic) 컴퓨터에 의해 지수 함수적 시간이 걸리는 알고리즘에 의해 풀릴 수 있다면 나머지 문제들도 마찬가지로 지수 함수적 시간이 걸리는 알고리즘에 의해 풀 수 있다. 이러한 관점에서 이 부류의 문제들은 서로 동등하다는 것이 증명될 수 있다. 아직까지는 아무도 NP-완전 문제를 결정적 컴퓨터에서 지수 함수적 시간에 풀 수 있는 알고리즘을 찾지 못하였지만, 앞으로도 아무도 이런 일을 하지 않을 것으로 보인다.
그러면 다음 문제점을 알아보자. 앞에서 이미 말한 대로, 인공 지능 분야를 설명하는 한 가지 방법은 인공 지능이 NP-완전 문제를 다항 함수적 시간에 풀려고 하는 것이다.
어떻게 이를 성취할 수 있는가에는 두 가지가 있다. 첫번째 방법은 비록 최악의 경우가 아니더라도 평균적으로 볼 때 빠르게 수행될 수 있는 알고리즘을 찾는 것이다. 두번째 방법은 만족할 수 있는 시간 내에 받아들일 수 있는 답을 구하는 근사적인 알고리즘을 찾는 것이다.
분기와 한계에 의한 방법 (branch-and-bound strategy) 은 평균적으로 볼 때 빠르게 수행될 수 있는 알고리즘의 하나이며, 이러한 종류의 알고리즘에 대하여 다음과 같은 사항이 말하여질 수 있다.
- 선택 과정이 완전하게 순서화되어 있을 때, 가장 좋은 경우의 성능.
- 선택 과정이 전혀 순서화되어 있지 않을 때부터 순서화되어 있을 때까지, 가장 나쁜 경우의 성능.
- 선택 과정이 임의로 되어 있을 때 (이를 위해 임의 과정을 사용할 수 있음), 이 경우의 평균적인 성능.
- 선택 과정이 경험적 함수를 특정한 문제 집합에 적용하여 순서화되어 있을 때의 현실 세계에서 평균적인 성능. 이 평균적인 성능은 앞의 임의 과정을 사용했을 때의 평균적인 성능보다 일반적으로 좋다고 알려져 있다.
그러나, 불행하게도 평균적인 시간이 걸리는 성능을 가진 방법이 사용되어도 실제로는 그 결과가 과히 만족스럽지 못한 경우가 많다. 심지어 분기와 한계에 의한 방법에서도 평균 시간은 지수 함수적이다. 그래서 완전 무결한 답보다는 답의 근사값으로 만족해야 될 필요가 있다. 앞의 제 2 장의 2-1-3 절에서 보여준 세일즈 맨의 방문을 위한 최단 이웃 알고리즘은 근사값을 구하는 방법의 좋은 예이다. 이 알고리즘을 수행하기 위해 걸리는 시간을 매우 쉽게 알 수 있다. 처음에 해야 될 일은 N 개의 도시를 방문하는 일정에 집어 넣는 것이다. 하나의 도시를 방문 일정에 집어 넣을 때마다 이 도시가 이미 방문 일정에 포함되어 있는가를 비교해야 한다. 이렇게 볼 때, 한 도시를 집어 넣을 때 평균적으로 (N - 1)/2 번 비교흘 하게 되고, 전체적으로 N(N - 1)/2 번 비교하게 된다. 이 알고리즘을 수행하기 위해 필요한 시간은 N(N - 1)/2 에 혹은 간단히 N2 에 비례함을 알 수 있다. 이는 지수 함수에 비례하는 시간보다 훨씬 빠르다. 다음은 이렇게 하여 답을 얻었을 때 얼마나 좋은가가 문제이다. 앞의 경우와 같이 성능면에서 고려될 수 있지만 답을 얻기 위해 필요한 시간보다도 답의 정확성에 대하여 알아보자.
- 가장 좋은 경우의 성능은 다음과 같이 간단하다. 근사값을 구하는 알고리즘도 주어진 문제에 따라 최적의 답을 구할 수 있다.
- 가장 나쁜 경우의 성능 : 최단 이웃 알고리즘의 경우 최악의 답과 최적의 답의 비율은 (logN + 1)/2 보다 크지는 않다는 것이 증명되었다.
- 도시가 임의로 흩어져 있을 때의 평균적인 성능 : 실제 자료에 의하면 이 경우의 성능이 최적의 경우보다 20 % 정도 뒤떨어진다.
- 도시의 분포가 자연적인 패턴을 따를 때 현실 세계에서의 평균적인 성능 : 이 문제는 대답하기가 매우 어려운 문제이다.
A* 알고리즘은 비교적 빠르고 정확한 답을 찾는 기법의 좋은 예이다. 만약 h' 의 h 를 과대 평가하여 계산되지 않는다면 A* 알고리즘은 최단 경로를 찾을 수 있다. 이러한 경우, 소요되는 시간은 h' 의 정확도에 달려 있다. 만약 h' 가 h 의 충분한 근사값을 계산할 수 있다면, 비록 경우에 따라서는 h' 가 부정확하여 탐색 시간이 좀 더 걸리는 상황이 몇 개 존재한다 하여도, A* 알고리즘은 대부분의 경우 꽤 효율적으로 수행된다. 평균적으로 A* 알고리즘이 얼마나 성능이 좋은가를 특정한 문제의 h' 로 표시해보자. 만약에 h' 에 대한 조건을 완화한다면 h 를 과대 평가하는 경우가 발생되어 최단 경로를 찾지 못할 수도 있다. 그러나 최적 경로와 이렇게 하여 얻어진 경로와의 가장 큰 차이는 (h' - h) 에 의한다. 그래서 만약 h' 의 오차를 제한할 수 있다면, 답의 오차도 제한될 수 있다. 풀기 어려운 문제를 해결하기 위하여 절대 오차가 아닌 평균적인 오차 차원에서 알고리즘을 고려할 수 있다. 이 경우 알려지지 않은 최적의 경우보다 평균 비용은 많이 들더라도 답을 구하기 위하여 걸리는 평균 시간에 대하여 말할 수 있다. 또한, 답을 구하는데 걸리는 시간과 답의 정확성과의 관계에 대하여 알고리즘을 고려할 수 있다.
평균적인 오차의 차원과, 답을 구하는데 걸리는 시간과 답의 정확성과의 관계를 A* 알고리즘에 적용하여 알아보자. 이를 위해 가장 좋은 경우와 가장 나쁜 경우의 성능을 분석한다. A* 알고리즘에서 최악의 경우의 성능은 사용되는 h' 의 함수로 기술된다. 그러나 인공 지능 분야의 문제들에 대하여, 최악의 경우와 최적의 경우의 성능에 대한 절대적 경계값에 관한 질문은 대부분의 경우 부적당하다. 이러한 경계값은 일반적으로 오차가 너무 크다. 왜냐하면, 인공 지능 분야에서 사용되는 구조, 즉 현실 세계의 복잡한 구조에 의한 여러 가지 제한 조건을 고려하지 않았기 때문이다. 인공 지능 분야에서는 평균적인 성능이 더욱 중요하다.
임의로 선택된 문제에서도 알고리즘의 평균 성능을 수리적으로 분석하는 일은 최악의 경우와 최적의 경우 성능 분석하는 일보다 어렵다. 평균적인 성능 분석을 몬테 칼로 기법을 사용한 시뮬레이션에 의해 수행하는 것이 가장 좋은 경우가 종종 있다. 현실 문제에서 평균적인 성능을 분석하기 위하여서는 문제의 분포에 대하여 수학적으로 기술하는 것이 불가능하기 때문에 몬테 카로 기법은 더욱 필요하다.
8. 요약
제 2 장에서는 인공 지능 분야의 문제를 풀기 위한 프로그램을 작성할 때 취해야 할 세가지 단계에 대해 설명했다. 이 단계는 다음과 같다.
1. 문제를 정확히 정의하라. 문제 공간, 공간 내에서의 움직임을 위한 연산자와 출발 상태 및 목표 상태를 규정하라.
2. 문제를 분석하여 일곱 개의 중요한 특징 중 문제가 속하는 곳을 정하라.
3. 지식을 표현하고 문제를 푸는 기법을 하나 이상 선택하여 이것을 문제에 적용하라.
이 장에서는 범용 문제 풀이 방법을 소개하여 위의 과정 중 세번째 단계에 대해 논의했다. 여러 중요한 면에서 보여준 알고리즘들이 다르다. 이는 다음과 같다.
- 탐색 과정의 각 단계에서 확장 전개될 노드를 선택하는 방법.
- 선택된 노드에 적용될 연산자의 선택 방법.
- 가장 좋은 답을 보장할 수 있는지의 여부.
- 주어진 상태를 한 번 이상 고려하여 끝낼 수 있는지의 여부.
- 탐색 과정을 통해 유지해야 할 상태 기술의 수.
- 특별한 탐색 경로를 포기해야만 하는 경우의 조건.
본 장에서는 여러 방법을 논의하면서 경험적 방법에 사용되는 평가 함수에 대하여 설명하였다. 또한 특정한 문제 영역에서 이러한 기법들이 지식을 사용하는 방법에 대해서도 암시적으로 설명하였다. 다음 장에서는 특정한 종류의 지식 구조를 차지하기 위해 적용되는 특수 목적의 문제 풀이 방법뿐만 아니라 그 지식을 표현하는 기법에 대해 다룬다.
9. 연습문제
1. 문제 풀이를 위한 탐색은 전진 (알려진 출발 상태로부터 목표 상태로) 혹은 후진 목표 상태로부터 출발 상태로) 으로 수행된다. 어떠한 요인에 의해 특정한 문제에 대한 방향의 선택이 결정되는가?
2. 만약 문제 풀이를 위한 탐색 프로그램이 다음 형태의 문제를 풀기 위해 작성된다면 탐색이 전진으로 혹은 후진으로 수행될지를 결정하라.
① 패턴인식 (pattern recognition)
② 블럭 세계 (blocks world)
③ 언어 이해 (language understanding)
3. 다음 문제에 대해 경험적 방법에 사용되는 적당한 평가 함수를 만들어 보아라.
① 블럭 세계
② 정리 증명 (theorem proving)
③ 선교사와 식인종 문제
4. 어떤 종류의 문제 공간에서 깊이 우선 탐색이 나비 우선 탐색보다 효과적인가?
5. 최적 우선 탐색이 단순한 나비 우선 탐색보다 부적합할 때는 언제인가?
6. A* 알고리즘의 첫 단계에 의해 다음 (1) 의 상황이 만들어졌다고 하자 (a + b 는 노드에서 h' 의 값이 a 이고 g 의 값이 b 임을 의미한다). 두번째 단계에서는 (2) 의 상황, 그리고 세번째 단계에서는 (3) 의 상황이 만들어졌다고 하자.
① 어떤 노드가 다음 단계에서 확장 전개되는가?
② 최적해가 발견된다고 보장할 수 있는가?
7. 알고리즘이 사이클을 포함한 그래프에서 적절하게 작용하는 이유는? 새로운 경로가 이미 존재하는 노드에서 만들어질 때, 만약 이 경로가 이미 만들어진 경로보다 부적합하다면 단순히 이 경로를 버림으로써 사이클을 방지할 수 있다.
만약 g 가 음이 아닌 수라면 사이클의 경로가 사이클이 없는 동일한 경로보다 결코 효과적일 수 없다. 예를 들어, 노드가 만들어진 순서대로 번호가 붙여져 있는 아래 그래프 (1) 을 보자. 노드 4 가 노드 6 의 후계 노드라는 사실을 단순히 기록할 수 없다. 이는 노드 6 을 지나는 경로가 노드 2 를 지나는 경로보다 길기 때문이다. 동일한 이유에 의해 노드 6 의 후계 노드로 노드 5 가 기록되는 것을 막을 수 있다.
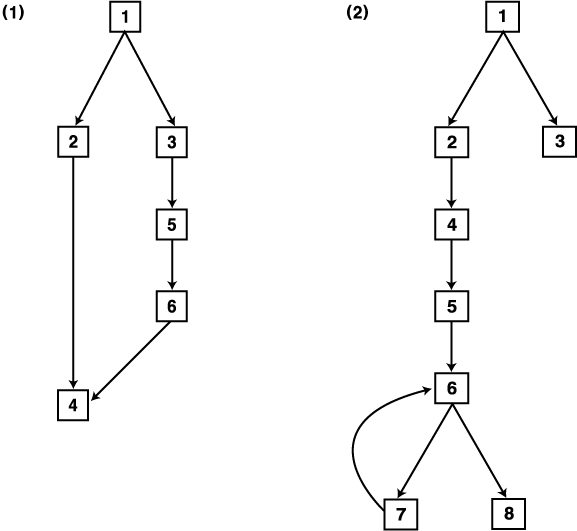
그러나 그래프 (2) 에서, 만약 7 로부터 노드 6 으로의 경로가 기록되지 않고 다음 단계에서 노드 7 이 노드 3 의 후계 노드라는 사실을 알게 된다면 어떠한 일이 발생하는가?
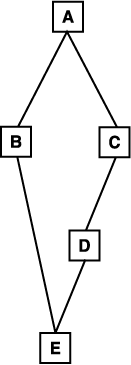
8. A* 알고리즘의 단계 2-3-1 에서는 S 에서 아무런 후계 노드도 가지지 않은 노드가 S 로부터 선택될 것을 요구한다. 그런 노드를 효과적으로 선택하기 위해 S 를 처리하는 방법을 어떻게 구현할 수 있는가? 노드 E 의 비용이 바뀔 경우, 구현된 기법이 다음 그래프에 적절하게 적용됨을 확인하라.
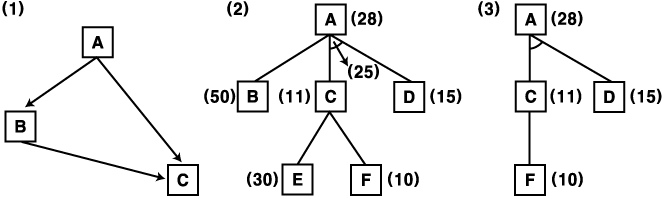
9. 사이클을 포함하는 그래프에 A* 알고리즘이 작용할 수 있도록 수정할 수 있다. 사이클을 방지하는데 필요한 일을 피하기 위해 이러한 A* 알고리즘을 사용할 수 있다. A* 알고리즘을 어떻게 변화시켜야 하나? 변화된 알고리즘을 아래 그래프 (1) 에 적용하여 노드 C 의 비용이 변했을 때 올바로 차지할 수 있는지 확인하라. 또한 그래프 (2) 와 (3) 에서, 노드 F 가 다음 단계로 전개 확장되고 노드 A 가 이것의 유일한 후계 노드라 가정할 때, 수정된 알고리즘에 의해 비용 전달이 올바르게 이루어지는가 확인하라.
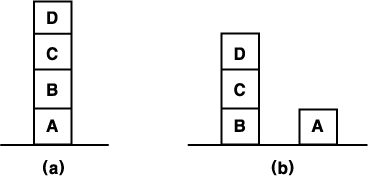
10. 아래 그림에서, (a) 처럼 배열된 상자를 (b) 와 같이 배열되도록 옮기는 문제를 풀려고 한다. 이때, pickup, putdown, stack, unstack 이라는 연산자를 사용한다. 언덕 오르기 방법을 사용하여 이 문제를 푸는 것이 합리적인가? 그 이유는?
11. 다음 암호 산술 문제를 풀기 위해 제한 조건의 만족 과정이 사용된다. 이 때, 이 과정의 수행을 추적하라.
CROSS
+ROADS
DANGER
12. 한 장소로부터 다른 장소로 옮겨가는 문제를 풀기 위해 방법-목적 분석 방법이 어떻게 사용되나 설명하라. 이 때, 이용할 수 있는 연산자는 walk, drive, take the bus, take a cab, fly 라고 가정하라.
13. 경험적 최적 우선 탐색 과정을 이용하여 어떤 문제를 푼다고 가정하자. 이러한 경우, 탐색 과정은 트리나 그래프를 사용하여 구현된다. 또한, 이 탐색 과정의 수행 중, 서로 다른 노드가 평균적으로 A 번 만들어진다고 가정하자. 이에 덧붙여 만약 그래프가 사용된다면, 이 탐색 과정은 평균적으로 노드가 이미 만들어져 있는가를 조사하는 시간만큼 걸리고, 노드가 이미 존재하는지의 여부가 조사되지 않는다면 B 개의 노드를 차지하는 시간만큼 걸린다. 어떠한 방법으로 그래프나 트리의 선택을 결정하는가? 파라미터 A 와 B 외에 어떠한 가정이 필요한가?
14. 근사값을 구하는 최단 이웃 알고리즘에서 최적값과 최악값의 비율이 (log N + 1)/2 보다 크지 않음을 증명하라.
책 읽는 방법을 바꾸면 인생이 바뀐다
백금산
[배운 점]
글을 열며
무엇이 가장 좋은 독서법인가?
가장 좋은 독서법이란 독서의 목적에 가장 잘 맞는 독서법이다.
독서의 목적과 독서방법의 종류는 얼마나 되는가?
독서의 목적은 여러 가지이다. 즐거움을 위한 독서와 인격 성숙을 위한 독서, 그리고 정보를 얻기 위한 독서로 나눌 수 있다.
독서의 방법도 여러 가지이다. 음독(소리내어 읽기)과 묵독(소리내지 않고 읽기)으로 나눌 수 있다.
독서하는 속도에 따라서 정독(천천히 읽기), 속독(빨리 읽기)으로 나눌 수 있다.
독서하는 분량에 따라 소독(조금 읽기)과 다독(많이 읽기)f 나눌 수 있다.
독서의 반복 여부에 따라 일독(한번 만 읽기)과 재독(반복해서 여러 번 읽기)로 나눌 수 있다.
독서의 범위에 따라서 완독(처음부터 끝까지 읽기)과 부분독(특정부분만 골라 읽기)으로 나눌 수도 있다.
독서하는 태도에 따라 숙독(철처하게 일기)과 개관독(대충 읽기)으로 나눌 수 있다.
독서의 방식에 따라 분석독(내용을 분해하면서 읽기)과 종합독(내용을 종합하면서 읽기)으로 나눌 수 있다.
정독과 재독은 인격 성숙과 신앙 성숙을 위한 독서의 가장 중요한 방법이다.
다독과 속독은 전문지식과 정보를 얻기 위한 독서의 가장 적합한 방법이다.
1장은 이러한 독서법들에 대한 기초적인 이해를 돕기 위해 독서법의 고전인 모티머 애들러 [독서법]에 대한 핵심을 요약하고
알기 쉽게 설명한다.
1_독서법의 기본기를 철저히 마스터하라
독서법을 배우려면 독서법의 명저부터 읽어라
어떤 새로운 분야를 공부할 때, 가장 빠르게 그 분야의 정상에 오르는 방법은 그 분야에서 가장 뛰어난 선생을 만나거나
가장 뛰어난 명저를 읽는 것이다.
독서법의 고전, 모티머 애들러의 [독서법]
모티머 애들러의 [독서법(How to read a book)]은 지금까지 독서법에 관해 쓰여진 책 가운데 가장 뛰어난 책 중의 하나다.
모티머 애들러의 [독서법]의 핵심 내용
1판에서 3판까지 발간된 [독서법]의 핵심은 1단계 개관독서법, 2단계 분석독서법, 3단계 종합독서법이다.
|
단계 |
내용 |
|
1단계 개관 독서법 |
점검 독서로서 대충 읽기, 훑어 읽기, 개관 읽기, 골라 읽기 |
|
2단계 분석 독서법 |
분석적 독서로서 철저하게 읽기, 꼼꼼하게 읽기, 씹어서 소화되도록 읽기 |
|
3단계 종합 독서법 |
종합적 독서로서 하나의 주제를 가지고 여러 권의 책을 비교하면서 읽는 방식이기 때문에 ‘주제별 독서법’ 혹은 ‘연역법적 독서법’이다. |
모티머 애들러의 [독서법]을 독파해서 얻는 유익
책 읽는 법은 글쓰는 법과는 그 과정이 정반대이다. 따라서 독서법의 기본기를 잘 익히는 것은 작문
법의 기본기를 잘 익히는 것이 될 수 있다. 왜냐하면 논술의 기본이 책읽기이기 때문이다.
실제로 독서법과 작문법은 모든 공부의 기초이다. 모든 학문의 기초는 바로 책읽기에서 시작한다.
독서관에 대한 패러다임 쉬프트: 독서는 기술이다
독서법은 이처럼 우리의 삶에 있어서 아주 중요하다.
독서는 단순한 ‘문자해독’이 아니라, 하나의 ‘기술’이다. 따라서 독서는 기술이기 때문에 독서에도 수준과 단계가 있다.
초급 단계의 개관 독서법
1) 골라 읽기
‘골라 읽기’는 책 전체를 읽지 않고 책의 한 부분만을 선택적으로 골라서 읽는 것이다. ‘골라 읽기’의 목적은
이 책의 내용이 내가 읽을 만한 가치와 필요가 있는 책인지 아닌지 가려 내기 위한 것이다.
첫째, 책의 성격과 핵심내용을 빨리 알려면, 속표지나 서문을 보면 된다.
둘째, 목차를 본다.
셋째, 색인을 본다.
넷째, 표지에 있는 광고문을 본다.
다섯째, 서론부분과 결론부분을 보면 된다.
이런 몇 부분을 골라서 읽으면 책의 전체 성격과 핵심내용을 개관할 수 있게 된다.
2) 대충 읽기
개관 독서법의 둘째는 ‘대충 읽기’이다. ‘대충 읽기’란 한 권의 책을 처음부터 끝까지 일사천리로 빨리 읽어 가는 것을 말한다.
이렇게 ‘대충 읽기’를 통해서 책의 전체적인 내용, 흐름, 윤곽을 잡는 것이다.
중급 단계의 분석 독서법
중급 단계의 분석 독서법은 내가 꼭 읽어야 하는 좋은 책의 내용을 완전히 파악해서 나의 것으로 만드는 독서법이다.
어떻게 한 권의 책을 나의 것으로 만들 수 있는가?
1) 분석 독서의 1단계: 책의 주제와 구조를 파악하라
책의 주제를 파악했다는 것은 한 권의 책의 내용을 하나의 문장으로 요약할 수 있다는 뜻이다.
즉, 적어도 3 내지 4개의 문장으로 책 전체를 요약할 수 있다는 뜻이다.
주제와 구조의 관련성
주제라는 내용물은 언제나 구조라는 그릇을 통해 표현된다.
글을 쓰는 사람은 먼저 주제를 선정하고, 그 주제에 맞는 구조를 결정해서 주제를 펼쳐 나가기 시작한다.
반대로 글을 읽는 사람은 먼저 구조를 파악해서 그 구조 속에 담긴 주제를 쉽게 파악할 수 있다.
2) 분석 독서의 2단계: 주제를 내 말로 풀어쓰거나 예를 들 수 있어야 이해된 것이다
주제를 파악하고 나면 현재 내가 이해하고 있는 수준의 언어로써 그것을 내 스스로 번역하고, 내 말로 풀어쓰는 방법을 계속해야
우리의 이해력이 증진되기 시작한다.
이해를 위해서는 전(前)이해가 필요하다
이해력이 증진되기 위해서는 해당 분야에 대한 사전 지식, 즉 전이해가 있어야 한다.
전이해가 많을수록 새로운 지식에 대한 이해가 잘 된다.
동일한 책을 읽고도 그 책의 내용을 잘 파악하는 것은 그 사람이 평상시 많은 분야의 독서를 통해 많은 사전 지식을 축적했기 때문이다.
좋은 선생이 되려면 자신이 가르치고자 하는 내용을 학생들이 이해할 수 있는 수준에 맞추어 전달해 주어야 한다.
즉, 학생들의 이해 수준에 맞추어 주는 눈높이 교육을 잘 해야 한다.
3) 분석 독서의 3단계: 이해한 내용에 대해 찬성과 반대를 표시하라
어떤 종류의 책이든지 간에 그 책의 내용을 받아들이거나 배척하는 것은 독자의 책임이다.
모티머 애들러의 [독서법]을 통해 배운 점
우선 ‘한 권의 책을 읽고 완전히 나의 것으로 만들었다’라고 말하려면 ‘어떤 상태까지 이르러야 하는가‘에 대한 것이다.
처음 초보자 때는 책을 의식적으로 끊어서 읽어야 한다. 책을 읽을 때에 ‘이 책의 주제는 무엇인가?’,
‘구조는 무엇인가’를 계속 질문하면서 읽어야 한다. 그 다음에는 계속 나의 말로써 풀어보려고 노력해야 한다.
그 다음에 또 의식적으로 계속 찬성도 해 보고, 반대도 해 보아야 한다.
분석 독서와 귀납법적 성경 공부
모티머 애들러가 말하는 이러한 분석 독서 방식은 소위 ‘귀납법적 성경연구 방법’과 같다.
귀납법적 성경 공부 방법에는 기본적으로 관찰․해석․적용의 3단계가 있다.
결국 성경을 귀납적으로 읽자는 말은 성경을 분석적으로 읽자는 것이다.
지적인 성장이 없는 곳에는 영적인 성장도 없다.
고급 단계의 종합 독서법
독서법의 마지막 고급 단계는 종합 독서법이다. 한 권의 책을 철저하게 독파하는 분석 독서법과는 달리 여러 권의 책을 주제별로
종합해서 읽는 방법이다.
1) 주제별로 읽어라
많은 책을 주제별로 읽을 때 우리는 비로소 하나의 주제나 사상에 대한 자기 나름대로의 체계적인 지식을 수립할 수 있다.
2) 한 주제를 비교하면서 읽어라
항상 단어의 의미는 문맥 속에서 결정된다. 즉, 저자가 사용하는 용어의 의미는 항상 저자가 사용하는 문맥 속에서 찾아야 한다.
3) 종합 독서법은 독서법의 최고봉
종합 독서법은 ‘개관 독서’와 ‘분석 독서’를 포함하며, 완성한다.
2_평생 인격 성숙을 위한 독서법 어떻게 할 것인가?
인격 성숙 혹은 신앙 성숙을 위한 독서란 무엇인가?
책을 읽는 중요한 목적 가운데 하나는 인격 성장 혹은 영적 성숙을 위한 것이다.
인격 성숙을 위한 독서란 독서를 통해 단편적인 지식과 정보만을 얻는 데 그치지 않고 인생의 바른 지혜를 얻고자 하는 것이다.
인생의 참 지혜란 세상과 자기를 바라보는 안목과 통찰력을 통해 세상과 인생의 목적을 바르게 아는 것이다.
한 권의 책을 마스터하라
1) 한 권의 책을 분석하며 읽어라
책을 읽을 때는 반드시 한가지 책을 습득하여 그 뜻을 모두 알아서
완전히 통달하고 의문이 없게 된 다음에야 다른 책을 읽을 것이요
많은 책을 읽어서 많이 얻기를 탐내어 부산하게 이것저것 읽지 말아야 한다
- 이이, 격몽요결 독서장 중에서
책을 읽는 데는 대개 방법이 있다.
세상에 도움이 되지 않는 책은 구름 가듯, 물 흐르듯 읽어도 되지만
만일 백성이나 나라에 도움이 되는 책이라면
반드시 문단마다 이해하고 구절마다 탐구해 가면서 읽어야 하며
한낮의 졸음이나 쫓는 태도로 읽어서는 안 된다.
- 다산 정약용의 독서론
2) 한 권의 책을 반복해서 읽어라
- 만 번씩 책 읽는 김득신(1604~1684)
- 천 번씩 책 읽는 사람들
- 세종대왕의 백독백습
어떤 책이든 밤을 새워 가며 읽으면서 한 번 읽고, 한 번 쓸 때마다 ‘바를 정(正)’자를 표시하면서 백 번 읽고 백 번을 썼다고 한다.
- 천로역정을 100번이나 읽은 스펄전
- 1년 만에 성경을 100번 읽은 김익두 목사
- 요한계시록을 만 번 읽은 길순주 목사
3) 한 권의 책을 암송하라
한 권을 마치면 반드시 그 책을 외우고 두 권을 마치면 내리 외었다.
이렇게 하기를 오래 하니 차츰 처음 배울 때와는 달랐다.
그리하여 3,4권을 읽게 되었을 때는 간혹 스스로 터득되는 바가 있었다.
- 퇴계 이황의 암기 독서법
4) 어떤 책을 철저히 읽을 것인가?
- 책 중의 책 성경 66권
- 고전과 명저 목록
- 20세기 교회를 움직인 100권의 책 (윌리엄 피터슨)
- 일반 분야의 고전 목록 (세계를 움직인 100권의 책)
한 사람의 스승을 마스터하라
신앙과 신학에 도움이 되는 영적 스승을 만나서 그 사람의 책을 전부 읽는 것이다.
독서의 균형을 맞추어라
1) 경건 독서와 신학 독서의 균형
균형있는 독서를 하십시오. 균형이 깨진 독서처럼 거짓된 지식을 낳는 것도 없습니다.
만일 신학 서적만 읽는다면 이러한 위험에 자신을 노출시키고 있는 것입니다.
그러므로 우리는 언제나 균형있는 식사를 하듯이 독서에서도 균형을 잡아야 합니다.
어떤 사람은 이것이 ‘무슨 뜻입니까?’ 라고 물을 것입니다.
제가 겸손하게 말씀드린다면 저에게 가장 큰 도움을 주었던 것은
신학 서적과 전기 읽는 것을 서로 균형 있게 한 것이었습니다.
저는 언제나 그렇게 했습니다.
항상 휴일에 그랬고, 매일같이 그렇게 하려고 합니다.
특히 휴일 아침에는 신학 서적을 읽고 밤에는 전기를 읽으려고 노력합니다.
- 로이드 존스, 1990
2) 고전 읽기와 신간 읽기의 균형
고전이란 시간의 테스트를 견뎌 낸 책이다.
서양 철학사는 플라톤의 각주에 불과하다는 말이 있다.
대부분의 고전은 인생의 가장 본질적이고 중요한 질문들을 다루고 있기 때문에 시대와 장소를 초월하는 가치를 지니고 있다.
고전을 읽지 않고 현대 신간들만 읽게 되면 논의의 초점과 방향을 잃버버리는 수가 많다.
C.S. 루이스는 고전 읽기의 중요성을 역설하면서 적어도 신간 3권에 고전 1권의 비율 정도로 균형을 맞출 것을 강조한다.
3_전문 지식을 얻기 위한 독서법 어떻게 할 것인가?
지식과 정보를 얻기 위한 실용적 독서란 무엇인가?
독서의 중요한 목적 가운데 하나는 독서를 통해 살아가는 데 필요한 실용적인 지식과 정보를 얻는 것이다.
전문가가 되려면 한 주제에 대해 많은 책을 읽어라
지식을 얻기 위한 독서는 다다익선(多多益善)이다.
1) 한 분야의 전문가가 되려면 얼마나 많은 책을 읽어야 하는가?
적어도 수백 권의 참고문헌을 읽어야 한다.
엘빈 토플러는 [미래쇼크]가 359권, [제3의 물결]이 534권, [권력이동]이 580권을 읽고 쓴 것이다.
톨스토이가 [전쟁과 평화]를 쓰기 위해 모은 참고자료는 작은 도서관 하나 정도의 분량이었다.
현재 일본 최고의 저널리스트로 알려진 다치바나 다카시의 경우 한 권의 책을 쓸 때, 즉 한 주제에 대해 글을 쓸 때
보통 큰 주제는 약 500여 권, 작은 주제는 약 100여 권 정도의 책을 읽는다.
어떤 분야에 대해서든지 어느 정도 전문적인 지식을 가지고 있다고 할 수 있으려면 한 주제에 대해 최소한 10권 이상의 책은 보아야 한다.
2) 한 분야의 많은 책을 읽으려면 어떤 순서로 책을 읽어야 하는가?
한 분야 혹은 한 주제에 대해 여러 권의 책을 읽을 때는 책을 읽는 순서가 필요하다.
일반적인 원칙은 ‘먼저 숲을 보고 그 다음에 나무를 보아야 한다’는 것이다.
첫째, 입문서를 읽어라. 중요한 점은 개론서나 입문서를 한 권만 보지 말고 여러 권을 보라는 것이다.
그냥 여러 권이 아니라 관점을 달리해서 쓰여진 입문서를 보는 것이 좋다.
둘째, 연구사를 읽어라.
연구사를 읽게 되면 그 분야의 핵심이 무엇인지를 금방 파악할 수 있다.
셋째, 관련 주제의 전문서적을 많이 읽어라.
하나의 주제를 심도 있게 연구한 책들을 중심으로, 연구하는 대상에 대한 이해를 넓혀가도록 한다.
성경읽기의 순서는 어떻게 하면 좋은가?
기본적으로 1년에 1번 이상은 성경 전체를 통독하는 것이 좋다.
성경을 공부하는 데는 다음과 같은 3가지 방식이 있다.
첫째, 성경이 배열된 순서에 따라 앞에서부터 차례로 한 권씩 공부하는 방법이 있다.
둘째는 이 순서를 거꾸로 하는 것이다. 예를 들어 복음서에 기록된 예수님을 먼저 공부하고 복음서의 관점에서 구약을 읽게 되면
구약의 큰 핵심과 줄기가 보이게 된다. 이것은 먼저 실물을 보고 그 다음에 조감도를 보는 것과 마찬가지다.
셋째로 성경을 중요도 순서대로 공부하는 방법을 사용할 수도 있다.
예를 들어 구약 중에서 창세기․출애굽기․시편․이사야, 신약 중에서 복음서․사도행전․로마서․요한계시록 등과 같은 성경책들은
하나님의 계시를 이해하는 데 있어서 상대적으로 다른 성경보다 비중이 있는 책들이다.
지도자가 되려면 다양한 주제에 대해 폭넓은 독서를 하라
1) 폭넓은 독서로 다방면의 전문가가 된 한․미․일의 대표적인 지식인들
한국의 소설가인 정을병은 약 3만 권의 책을 읽었다고 한다. 그는 일주일에 2~3번씩 서점에 가서 한 번에 2~3권 정도의 책을 사고,
한 주에 3~4권 정도의 책을 읽고, 한 달에 15권 정도의 책을 꾸준히 읽는다고 한다. 이런 생활을 수십 년간 반복하면서
자신의 전공분야인 소설분야와 다른 관심 있는 여 러 분야의 전문 지식인으로서 활동할 수 있었다고 한다.
최근 ‘지(知)의 거장’으로 불리며 한국 독서계에 상당한 반향을 불러일으키고 있는 일본의 저널리스트 다치바나 다카시는
자신이 알고 싶은 분야를 연구할 때 기본적으로 1m 높이 분량의 책을, 큰 주제일 경우에는 3~4m 높이 분량의 책을 독파한다고 한다.
‘경영학의 아버지’로 불리는 피터 드러커는 다음과 같이 말한다.
“나는 3년 또는 4년 마다 다른 주제를 선택한다. 그 주제는 통계학중세 역사 일본 미술 경제학 등 매우 다양하다.
3년 정도 공부한다고 해서 그 분야를 완전히 터득할 수는 없겠지만 그 분야가 어떤 것인지를 이해하는 정도는 충분히 가능하다.
그런 식으로 나는 60여년 이상 동안 3년 내지 4년마다 주제를 바꾸어 공부를 계속해 오고 있다.
이 방법은 나에게 상당한 지식을 쌓을 수 있도록 해 주었을 뿐만 아니라 나로 하여금 새로운 주제와 새로운 시각 그리고
새로운 방법에 대한 개방적인 자세를 취할 수 있도록 해 주었다.”
2) 폭넓은 독서로 자기 분야의 정상을 이룬 사람들
- 아리스토텔레스의 제자였던 알렉산더 대왕
- 나폴레옹 황제, 그는 4주간 이집트 원정을 떠날 때 1,000권의 책을 싣고 떠났다고 한다.
- 싱가포르의 국부 리콴유, ‘싱가포르 건설은 자신의 독서 상상력에서 비롯된 것’이라고 말한다.
- 중국의 국부 모택동, 10만리 대장정 중에 말라리아에 걸려 들것에 실려 가면서도 책을 읽었다.
- 에디슨․헬렌 켈러․손정의․오프라 윈프리
3) 평생 독서대학에서 폭넓은 독서를 하는 지도자들
큰 인물, 큰 사람이 되기 위해서는 폭넓은 독서가 필요하다
‘지도자는 독서가(Leader is a reader)'라는 말이 있다.
독서대학은 평생대학이다
사람은 대학에서 전공을 택하게 되지만, 그것에는 한계가 있다.
그러나 독서로써는 대학을 몇 개라도 나올 수가 있다. 다만 학위만 없을 뿐이다.
그러나 학위 같은 형식적인 것이 무슨 소용이 있는가.
오늘날의 시대는 그런 형식적인 것으로는 먹고 살 수가 없다,
실제로 할 수 있는 것이 무엇이냐가 중요한 것이고,
그 할 수 있는 것도 어느 정도의 수준이냐 하는 것이 문제인 것이다.
- 소설가 정을병, 2002
공부를 하려면 독서대학에 들어가라. 독서대학은 평생대학이다.
현대사회에서는 끊임없이 지식이 확대․재생산되고 있기 때문에 옛날 대학시절에 배운 지식만 가지고는
전문분야에서 살아갈 수가 없다. 요즈음은 얼마나 빠르게 지식이 새로워지고 있는지 5년 정도만 지나면 각종 전문분야의 지식이 바뀐다.
책을 읽으면 누구나 전문가가 될 수 있다
적어도 한 분야의 책을 100권 정도만 읽는다면 어느 정도 그 분야의 전문지식을 가질 수 있다.
3일에 1권을 읽어서 3년만 투자한다 해도 역시 300권 이상의 책을 읽을 수 있다.
한 분야에 대한 책을 300권 이상만 읽는다면 누구라도 그 분야에서 전문가가 될 수 있다.
많은 책을 읽기 위해서는 ‘속독’을 하라
지식과 정보를 얻기 위한 독서의 첫 번째 비결은 ‘다독’ 이다. 다독을 위해서는 속독이 필요하다.
속독의 방법론에는 두 가지가 있다. ‘눈 운동을 통한 속독법’과 ‘기술적 속독법’ 이다.
1) 눈 운동을 통한 속독법
먼저 눈 속독법이란 책 읽는 눈의 기능을 강화시켜 책을 빨리 읽으려는 것이다. 그러나 이러한 속독법에는 한계가 있다.
이해력이 동반되지 않는 기계적인 속독법은 아무런 소용이 없다.
2) 골라 읽기를 통한 속독법
첫째, 속독을 하기 위해서는 책을 전부 다 읽지 말고 필요한 부분만 발췌해서 골라 읽기를 해야 한다.
발췌독은 속독의 자연스러운 방법 가운데 하나이다.
이처럼 책을 빨리 읽기 위해서는 책을 읽을 때 반드시 ‘커버에서 커버까지 이 잡듯이 샅샅이 읽어야 한다’는 고정관념을 깨야 한다.
3) 문단 읽기를 통한 속독법
둘째, 속독을 하기 위해서는 책을 문단 단위로 읽어야 한다.
아무리 긴 책이라 할지라도 생각의 기본적인 단위는 약 200자 원고지 1매 정도로 이루어진 단락이다.
우리는 이러한 단락을 문단이라고 부른다. 이렇게 단락 단위로 책을 읽어도 책의 내용과 정보를 알
수가 있다. 왜냐하면 글의 짜임새는 한 단락이 기본이기 때문이다.
[느낀 점]
책 읽는 것을 좋아해서 자연스럽게 ‘효과적인 독서법’에 관심을 가지게 되었다.
‘독서는 즐거움을 주는 취미’였던 나에게 ‘독서는 기술이다’ 이라는 관점에서 접근한 이 책은 많은 도움을 주었다.
그저 읽고 즐기는 것에 머물러 있던 나의 독서습관을 ‘분석적 독서’의 관점에서 책을 읽고 나서 ‘배느실‘을 정리하는
동기를 부여해 주었고, ’종합적 독서‘에 대한 새로운 시각을 열어주어서 ‘주제가 있는’ 독서를 하고 싶게 해 주었다.
[실천할 점]
1. 정독의 필요를 느끼는 책은 꾸준히 ‘배느실’ 의 습관을 갖는다.
2. 한 권의 책을 읽고 나면 ‘배느실’을 정리할 때 나의 말로 책의 ‘주제’를 적는다.
3. 앞으로 3년 간은 ‘코칭’을 주제로 한 책을 300권 이상 읽는다.
4. 코칭관련 책들과 더불어 ‘인문학 서적’을 틈틈이(한 달에 1권 이상) 읽는다.
[출처] 책읽는 방법을 바꾸면 인생이 바뀐다 - 독서법|작성자 대장
 Nirvana_Ambient_Radio.5238757.TPB.torrent
Nirvana_Ambient_Radio.5238757.TPB.torrenthttp://kin.naver.com/qna/detail.nhn?d1id=11&dirId=110801&docId=59394136&qb=6riA7J2YIOyghOqwnOuwqeyLnQ==&enc=utf8§ion=kin&rank=2&search_sort=0&spq=0&pid=ghIAQloi5UKssZtyRJVsss--035103&sid=TY6iA6Bwjk0AAC8ZIpU
글의 전개방식
이 2가지를 나는 썼고 논증에 대한 내용을 추가한다
|
3. 배열방식.
① 시간적 전개 : 시간적 순서에 따라 제재를 배열하는 방법.
② 공간적 전개 : 제재의 놓인 순서에 따라, 장소의 이동에 따라 제제를 배열하는 방법.
③ 열거식 전개 : 대등한 자격의 제재를 나란히 배열하는 방법.
④ 점층적 전개 : 중요성의 정도에 따라 순서대로 배열하는 방법.
---------------------- 진술방식과 전개방식의 차이점이 먼가여? 간략히 설명 드리겠습니다. ^^
''진술방식''이라는 것은 글을 쓰는 목적에 따라, 글 전체를 어떻게 써 나가야 할 것인가를 결정해서 표현하는 것을 말합니다.
전체적으로 싸가지(네가지)가 있습니다. ^^
ㄱ.설명 - 쉽죠? 설명하는 방식으로 글을 쓴다는 말입니다. 예를 들면 설명문과 같은 정보전달을 목적으로 하는 글들이 이 같은 방식을 쓰겠죠? ^^
ㄴ.논증 - 주장에 대해 증명을 해 나가는 글에 어울리겠죠? 눈치도 빠르시지!! 그렇죠~ 논설문과 같이 의견이나 주장을 증명하는 방식의 글에 씁니다.
ㄷ.서사 - 이 놈은 말은 어려운데, 간단히 정리하면 ''시간의 흐름에 따른 이야기 구조''라고 합니다. 보통은 '소설'에서 잘 나타나죠. 인물의 행동을 통해서 보여 주기, 시간적 배경의 나열, 사건의 진행 등으로 이 '서사'라는 놈은 나타납니다.
ㅁ.묘사 - 친구가 어제 '비'의 콘서트 다녀온 이야기를 합니다. 그럼 비가 가장 중심 소재가 되겠죠. 머리 모양부터 발끝까지, 열정적인 춤과 노래 등을 마치 말로 그림을 그리듯 상세히 설명을 해주죠? 그럼 듣는 사람은 머릿속에 듣고 있는 것을 그려봅니다. 바로 이것!!! 이 묘사입니다. 쉽죠? ^^
''전개방식" 이 건 시간 관계상 더 간단히 설명할게요.
주제를 정하고 글을 써 나갈 때 글 안에서 이야기 할 많은 내용들을 다양한 방법으로 풀어 갑니다. 이 때 쓰는 것이 '글의 전개 방식'이라고 하는 것입니다.
*다른 곳에서 빌려 온 자료입니다. ^^
(동태적 범주) -서사 : 시간의 흐름에 따른 사건의 진행을 중시하는 전개방법
-인과 : 일어난 일의 원인과 결과를 엮어서 밝히는 전개방법
-과정 : 어떤 일의 절차와 순서를 밝히는 전개방법
(정태적 범주) -논리 : 정태적 범주에 따로 <논리>라고 설정하지는 않습니다. <인과>와 같은 방법이 논리에 해당하는 것 같은데요?
-정의 : 개념의 내용, 성격 등을 엄밀하게 제한해서 규정하는 진술방식
-지정,확인 : “○○는 무엇이다” 하는 물음에 답하는 것과 같은 진술방식
-비교,대조 : 비교는 비슷함을 전제로 어떻게 같은가를 찾는 것이고, 대조는 서로 다름을 전제로 어떻게 다른가를 찾음
-분류(구분) : 동일한 기준에 의해 어떤 생각이나 대상을 구분 짓는 방법
-분석 : 사실이나 사물을 부분으로 나누어 각 구성요소를 분해하는 방법
-묘사 : 어떤 대상을 눈에 보이듯이 그려내는 전개 방법
-예시 : 구체적인 예를 들어 설명하는 방법 |
|
|